开发者指南
1. 概览
IvorySQL在开源PostgreSQL数据库的基础上提供独特的附加功能。
IvorySQL致力于通过创新和建立在开源数据库解决方案之上为其终端用户提供价值。我们的目标是为中小型企业提供一个具有高性能、可扩展性、可靠性和易于使用的解决方案。
IvorySQL提供的扩展功能将使用户能够建立高性能和可扩展的PostgreSQL数据库集群,具有更好的数据库兼容性和管理。这简化了从其他DBMS迁移到PostgreSQL的过程,增强了数据库管理经验。
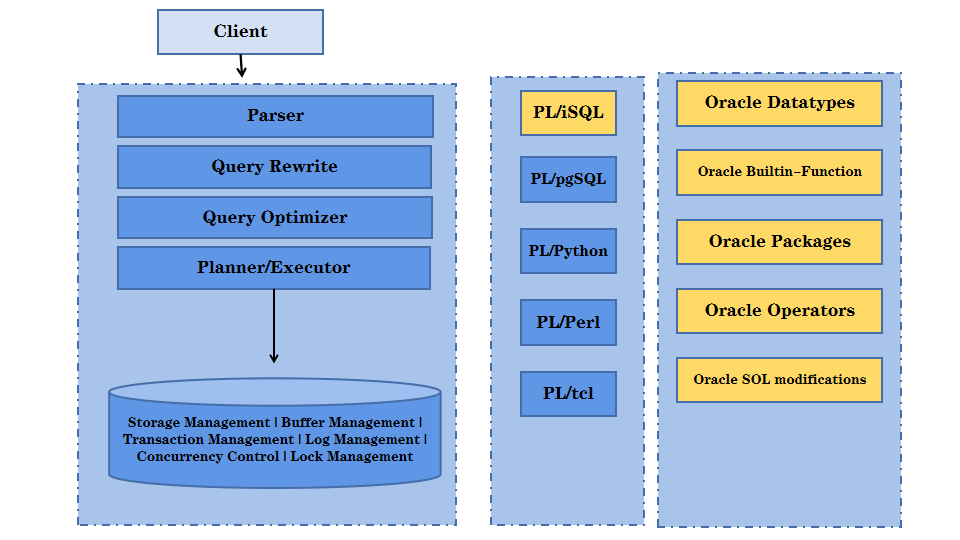
2. 数据库建模(第一章创建库+第二章创建表)
2.1. 创建一个数据库
看看你能否访问数据库服务器的第一个例子就是试着创建一个数据库。 一台运行着的IvorySQL服务器可以管理许多数据库。 通常我们会为每个项目和每个用户单独使用一个数据库。
你的站点管理员可能已经为你创建了可以使用的数据库。 如果这样你就可以省略这一步, 并且跳到下一节。
要创建一个新的数据库,在我们这个例子里叫`mydb`,你可以使用下面的命令:
$ createdb mydb如果不产生任何响应则表示该步骤成功,你可以跳过本节的剩余部分。
如果你看到类似下面这样的信息:
createdb: command not found那么就是IvorySQL没有安装好。或者是根本没安装, 或者是你的shell搜索路径没有设置正确。尝试用绝对路径调用该命令试试:
$ /usr/local/pgsql/bin/createdb mydb在你的站点上这个路径可能不一样。和你的站点管理员联系或者看看安装指导获取正确的位置。
另外一种响应可能是这样:
createdb: error: connection to server on socket "/tmp/.s.PGSQL.5432" failed: No such file or directory
Is the server running locally and accepting connections on that socket?这意味着该服务器没有启动,或者在`createdb`期望去连接它的时候没有在监听。同样, 你也要查看安装指导或者咨询管理员。
另外一个响应可能是这样:
createdb: error: connection to server on socket "/tmp/.s.PGSQL.5432" failed: FATAL: role "joe" does not exist在这里提到了你自己的登录名。如果管理员没有为你创建IvorySQL用户帐号, 就会发生这些现象。(IvorySQL用户帐号和操作系统用户帐号是不同的。) 如果你是管理员,参阅 第 22 章 获取创建用户帐号的帮助。 你需要变成安装IvorySQL的操作系统用户的身份(通常是 postgres)才能创建第一个用户帐号。 也有可能是赋予你的IvorySQL用户名和你的操作系统用户名不同; 这种情况下,你需要使用`-U`选项或者使用`PGUSER`环境变量指定你的IvorySQL用户名。
如果你有个数据库用户帐号,但是没有创建数据库所需要的权限,那么你会看到下面的信息:
createdb: error: database creation failed: ERROR: permission denied to create database并非所有用户都被许可创建新数据库。 如果IvorySQL拒绝为你创建数据库, 那么你需要让站点管理员赋予你创建数据库的权限。出现这种情况时请咨询你的站点管理员。 如果你自己安装了IvorySQL, 那么你应该以你启动数据库服务器的用户身份登录然后参考手册完成权限的赋予工作。 [1]
你还可以用其它名字创建数据库。IvorySQL允许你在一个站点上创建任意数量的数据库。 数据库名必须是以字母开头并且小于 63 个字符长。 一个方便的做法是创建和你当前用户名同名的数据库。 许多工具假设该数据库名为缺省数据库名,所以这样可以节省你的敲键。 要创建这样的数据库,只需要键入:
$ createdb如果你再也不想使用你的数据库了,那么你可以删除它。 比如,如果你是数据库`mydb`的所有人(创建人), 那么你就可以用下面的命令删除它:
$ dropdb mydb(对于这条命令而言,数据库名不是缺省的用户名,因此你就必须声明它) 。这个动作将在物理上把所有与该数据库相关的文件都删除并且不可取消, 因此做这中操作之前一定要考虑清楚。
2.2. 创建一个新表
你可以通过指定表的名字和所有列的名字及其类型来创建表∶
CREATE TABLE weather (
city varchar(80),
temp_lo int, -- 最低温度
temp_hi int, -- 最高温度
prcp real, -- 湿度
date date
);你可以在`psql`输入这些命令以及换行符。`psql`可以识别该命令直到分号才结束。
你可以在 SQL 命令中自由使用空白(即空格、制表符和换行符)。 这就意味着你可以用和上面不同的对齐方式键入命令,或者将命令全部放在一行中。两个划线(“--”)引入注释。 任何跟在它后面直到行尾的东西都会被忽略。SQL 是对关键字和标识符大小写不敏感的语言,只有在标识符用双引号包围时才能保留它们的大小写(上例没有这么做)。
varchar(80)`指定了一个可以存储最长 80 个字符的任意字符串的数据类型。`int`是普通的整数类型。`real`是一种用于存储单精度浮点数的类型。`date`类型应该可以自解释(没错,类型为`date`的列名字也是`date。 这么做可能比较方便或者容易让人混淆 — 你自己选择)。
IvorySQL支持标准的SQL类型`int`、smallint、real、double precision、char(`N)、`varchar(`N)、`date、time、timestamp`和`interval,还支持其他的通用功能的类型和丰富的几何类型。IvorySQL中可以定制任意数量的用户定义数据类型。因而类型名并不是语法关键字,除了SQL标准要求支持的特例外。
第二个例子将保存城市和它们相关的地理位置:
CREATE TABLE cities (
name varchar(80),
location point
);类型`point`就是一种IvorySQL特有数据类型的例子。
最后,我们还要提到如果你不再需要某个表,或者你想以不同的形式重建它,那么你可以用下面的命令删除它:
DROP TABLE tablename;3. 写入数据(SQL写入)参考第 6 章 数据操纵
当一个表被创建后,它不包含任何数据。在数据库发挥作用之前,首先要做的是插入数据。一次插入一行数据。你也可以在一个命令中插入多行,但不能插入不完整的行。即使只知道其中一些列的值,也必须创建完整的行。
CREATE TABLE products (
product_no integer,
name text,
price numeric
);一个插入一行的命令将是:
INSERT INTO products VALUES (1, 'Cheese', 9.99);数据的值是按照这些列在表中出现的顺序列出的,并且用逗号分隔。通常,数据的值是文字(常量),但也允许使用标量表达式。
上面的语法的缺点是你必须知道表中列的顺序。要避免这个问题,你也可以显式地列出列。例如,下面的两条命令都有和上文那条 命令一样的效果:
INSERT INTO products (product_no, name, price) VALUES (1, 'Cheese', 9.99);
INSERT INTO products (name, price, product_no) VALUES ('Cheese', 9.99, 1);许多用户认为明确列出列的名字是个好习惯。
如果你没有获得所有列的值,那么你可以省略其中的一些。在这种情况下,这些列将被填充为它们的缺省值。例如:
INSERT INTO products (product_no, name) VALUES (1, 'Cheese');
INSERT INTO products VALUES (1, 'Cheese');第二种形式是IvorySQL的一个扩展。它从使用给出的值从左开始填充列,有多少个给出的列值就填充多少个列,其他列的将使用缺省值。
为了保持清晰,你也可以显式地要求缺省值,用于单个的列或者用于整个行:
INSERT INTO products (product_no, name, price) VALUES (1, 'Cheese', DEFAULT);
INSERT INTO products DEFAULT VALUES;你可以在一个命令中插入多行:
INSERT INTO products (product_no, name, price) VALUES
(1, 'Cheese', 9.99),
(2, 'Bread', 1.99),
(3, 'Milk', 2.99);也可以插入查询的结果(可能没有行、一行或多行):
INSERT INTO products (product_no, name, price)
SELECT product_no, name, price FROM new_products
WHERE release_date = 'today';这提供了用于计算要插入的行的SQL查询机制( 第 7 章 )的全部功能。
4. 查询数据 参考 第七章查询的组合查询 第十五章 并行查询
4.1. 组合查询
两个查询的结果可以用集合操作并、交、差进行组合。语法是
query1 UNION [ALL] query2
query1 INTERSECT [ALL] query2
query1 EXCEPT [ALL] query2query1*和query2*都是可以使用以上所有特性的查询。集合操作也可以嵌套和级连,例如
query1 UNION query2 UNION query3实际执行的是:
(query1 UNION query2) UNION query3UNION`有效地把*`query2的结果附加到query1*的结果上(不过我们不能保证这就是这些行实际被返回的顺序)。此外,它将删除结果中所有重复的行, 就象`DISTINCT`做的那样,除非你使用了`UNION ALL`。
INTERSECT`返回那些同时存在于*`query1和query2*的结果中的行,除非声明了`INTERSECT ALL`, 否则所有重复行都被消除。
EXCEPT`返回所有在*`query1的结果中但是不在query2的结果中的行(有时侯这叫做两个查询的*差)。同样的,除非声明了`EXCEPT ALL`,否则所有重复行都被消除。
为了计算两个查询的并、交、差,这两个查询必须是“并操作兼容的”,也就意味着它们都返回同样数量的列, 并且对应的列有兼容的数据类型,如 第 10.5 节 中描述的那样。
4.2. 并行查询
4.2.1. 并行查询如何工作
当优化器判断对于某一个特定的查询,并行查询是最快的执行策略时,优化器将创建一个查询计划。该计划包括一个 *Gather*或者*Gather Merge*节点。下面是一个简单的例子:
EXPLAIN SELECT * FROM pgbench_accounts WHERE filler LIKE '%x%';
QUERY PLAN
-------------------------------------------------------------------------------------
Gather (cost=1000.00..217018.43 rows=1 width=97)
Workers Planned: 2
-> Parallel Seq Scan on pgbench_accounts (cost=0.00..216018.33 rows=1 width=97)
Filter: (filler ~~ '%x%'::text)
(4 rows)在所有的情形下,`Gather`或*Gather Merge*节点都只有一个子计划,它是将被并行执行的计划的一部分。如果`Gather`或*Gather Merge*节点位于计划树的最顶层,那么整个查询将并行执行。如果它位于计划树的其他位置,那么只有查询中在它之下的那一部分会并行执行。在上面的例子中,查询只访问了一个表,因此除`Gather`节点本身之外只有一个计划节点。因为该计划节点是`Gather`节点的孩子节点,所以它会并行执行。
使用 EXPLAIN 命令, 你能看到规划器选择的工作者数量。当查询执行期间到达`Gather`节点时,实现用户会话的进程将会请求和规划器选中的工作者数量一样多的 后台工作者进程 。规划器将考虑使用的后台工作者的数量被限制为最多 max_parallel_workers_per_gather 个。任何时候能够存在的后台工作者进程的总数由 max_worker_processes 和 max_parallel_workers 限制。因此,一个并行查询可能会使用比规划中少的工作者来运行,甚至有可能根本不使用工作者。最优的计划可能取决于可用的工作者的数量,因此这可能会导致不好的查询性能。如果这种情况经常发生,那么就应当考虑一下提高`max_worker_processes`和`max_parallel_workers`的值,这样更多的工作者可以同时运行;或者降低`max_parallel_workers_per_gather`,这样规划器会要求少一些的工作者。
为一个给定并行查询成功启动的后台工作者进程都将会执行计划的并行部分。这些工作者的领导者也将执行该计划,不过它还有一个额外的任务:它还必须读取所有由工作者产生的元组。当整个计划的并行部分只产生了少量元组时,领导者通常将表现为一个额外的加速查询执行的工作者。反过来,当计划的并行部分产生大量的元组时,领导者将几乎全用来读取由工作者产生的元组并且执行`Gather`或`Gather Merge`节点上层计划节点所要求的任何进一步处理。在这些情况下,领导者所作的执行并行部分的工作将会很少。
当计划的并行部分的顶层节点是`Gather Merge`而不是`Gather`时,它表示每个执行计划并行部分的进程会产生有序的元组,并且领导者执行一种保持顺序的合并。相反,`Gather`会以任何方便的顺序从工作者读取元组,这会破坏可能已经存在的排序顺序。
4.2.2. 何时会用到并行查询?
有几种设置会导致查询规划器在任何情况下都不生成并行查询计划。为了让并行查询计划能够被生成,必须配置好下列设置。
-
max_parallel_workers_per_gather 必须被设置为大于零的值。这是一种特殊情况,更加普遍的原则是所用的工作者数量不能超过`max_parallel_workers_per_gather`所配置的数量。
此外,系统一定不能运行在单用户模式下。因为在单用户模式下,整个数据库系统运行在单个进程中,没有后台工作者进程可用。
如果下面的任一条件为真,即便对一个给定查询通常可以产生并行查询计划,规划器都不会为它产生并行查询计划:
-
查询要写任何数据或者锁定任何数据库行。如果一个查询在顶层或者 CTE 中包含了数据修改操作,那么不会为该查询产生并行计划。一种例外是,
CREATE TABLE … AS、`SELECT INTO`以及`CREATE MATERIALIZED VIEW`这些创建新表并填充它的命令可以使用并行计划。 -
查询可能在执行过程中被暂停。只要在系统认为可能发生部分或者增量式执行,就不会产生并行计划。例如:用 DECLARE CURSOR 创建的游标将永远不会使用并行计划。类似地,一个`FOR x IN query LOOP .. END LOOP`形式的 PL/pgSQL 循环也永远不会使用并行计划,因为当并行查询进行时,并行查询系统无法验证循环中的代码执行起来是安全的。
-
使用了任何被标记为`PARALLEL UNSAFE`的函数的查询。大多数系统定义的函数都被标记为`PARALLEL SAFE`,但是用户定义的函数默认被标记为`PARALLEL UNSAFE`。参见 第 15.4 节 中的讨论。
-
该查询运行在另一个已经存在的并行查询内部。例如,如果一个被并行查询调用的函数自己发出一个 SQL 查询,那么该查询将不会使用并行计划。这是当前实现的一个限制,但是或许不值得移除这个限制,因为它会导致单个查询使用大量的进程。
即使对于一个特定的查询已经产生了并行查询计划,在一些情况下执行时也不会并行执行该计划。如果发生这种情况,那么领导者将会自己执行该计划在`Gather`节点之下的部分,就好像`Gather`节点不存在一样。上述情况将在满足下面的任一条件时发生:
-
因为后台工作者进程的总数不能超过 max_worker_processes,导致不能得到后台工作者进程。
-
由于为并行查询目的启动的后台工作者数量不能超过 max_parallel_workers 这一限制而不能得到后台工作者。
-
客户端发送了一个执行消息,并且消息中要求取元组的数量不为零。执行消息可见 扩展查询协议 中的讨论。因为 libpq 当前没有提供方法来发送这种消息,所以这种情况只可能发生在不依赖 libpq 的客户端中。如果这种情况经常发生,那在它可能发生的会话中设置 max_parallel_workers_per_gather 为零是一个很好的主意,这样可以避免产生连续运行时次优的查询计划。
4.2.3. 并行计划
因为每个工作者只执行完成计划的并行部分,所以不可能简单地产生一个普通查询计划并使用多个工作者运行它。每个工作者都会产生输出结果集的一个完全,因而查询并不会比普通查询运行得更快甚至还会产生不正确的结果。相反,计划的并行部分一定被查询优化器在内部当作一个*部分计划*,即它必须被构建出来,这样每一个执行该计划的进程将以无重复地方式产生输出行的一个子集,即保证每一个所需要的输出行正好只被一个合作进程生成。通常,这意味着该查询的驱动表上的扫描必须是一种可并行的扫描。
4.2.3.1. 并行扫描
当前支持下列可并行的表扫描。
-
在一个*并行顺序扫描\*中,表块将在合作进程之间被划分。一次会分发一个块,这样对表的访问还是保持顺序方式。
-
在一个*并行位图堆扫描\*中,一个进程被选为领导者。这个进程执行对一个或者多个索引的扫描并且构建出一个位图指示需要访问哪些表块。这些表块接着会在合作进程之间划分(和并行顺序扫描中一样)。换句话说,堆扫描以并行方式进行但底层的索引扫描不是并行。
-
在一个*并行索引扫描\*或者*并行只用索引的扫描\*中,合作进程轮流从索引读取数据。当前,并行索引扫描仅有B-树索引支持。每一个进程将认领一个索引块并且扫描和返回该索引块引用的所有元组,其他进程可以同时地从一个不同的索引块返回元组。并行B-树扫描的结果会以每个工作者进程内的顺序返回。
其他扫描类型(例如非B-树索引的扫描)可能会在未来支持并行扫描。
4.2.3.2. 并行连接
正如在非并行计划中那样,驱动表可能被使用嵌套循环、哈希连接或者归并连接连接到一个或者多个其他表。连接的内侧可以是任何类型的被规划器支持的非并行计划,假设它能够安全地在并行工作者中运行。根据连接类型,内侧还可以是一种并行计划。
-
在一个*嵌套循环连接\*中,内侧总是非并行的。尽管它会被完全执行,如果内侧是一个索引扫描也会很高效,因为外侧元组以及在索引中查找值的循环会被划分到多个合作进程。
-
在一个*归并连接\*中,内侧总是一个非并行计划并且因此会被完全执行。这可能是不太高效的,特别是在排序必须被执行时,因为在每一个合作进程中工作数据和结果数据是重复的。
-
在一个哈希连接\(没有“并行”前缀)中,每个合作进程都会完全执行内侧以构建哈希表的相同。如果哈希表很大或者该计划开销很大,这种方式就很低效。在一个并行哈希连接\*中,内侧是一个*并行哈希\,它把构建共享哈希表的工作划分到多个合作进程。
4.2.3.3. 并行聚集
IvorySQL通过按两个阶段进行聚集来支持并行聚集。首先,每个参与到查询并行部分的进程执行一个聚集步骤,为该进程注意到的每个分组产生一个部分结果。这在计划中反映为一个`Partial Aggregate`节点。然后,部分结果通过`Gather`或者`Gather Merge`被传输到领导者。最后,领导者对来自所有工作者的结果进行重新聚集得到最终的结果。这在计划中反映为一个`Finalize Aggregate`节点。
因为`Finalize Aggregate`节点运行在领导者进程上,如果查询产生的分组数相对于其输入行数来说比较大,则查询规划器不会喜欢它。例如,在最坏的情况下,`Finalize Aggregate`节点看到的分组数可能与所有工作者进程在`Partial Aggregate`阶段看到的输入行数一样多。对于这类情况,使用并行聚集显然得不到性能收益。查询规划器会在规划过程中考虑这一点并且不太会在这种情况下选择并行聚集。
并行聚集并非在所有情况下都被支持。每一个聚集都必须是对并行 安全的 并且必须有一个组合函数。如果该聚集有一个类型为`internal`的转移状态,它必须有序列化和反序列化函数。更多细节请参考 CREATE AGGREGATE。如果任何聚集函数调用包含`DISTINCT`或`ORDER BY`子句,则不支持并行聚集。对于有序集聚集或者当查询涉及`GROUPING SETS`时,也不支持并行聚集。只有在查询中涉及的所有连接也是该计划并行部分的组成部分时,才能使用并行聚集。
4.2.3.4. 并行Append
只要当IvorySQL需要从多个源中整合行到一个单一结果集时,它会使用`Append`或`MergeAppend`计划节点。在实现`UNION ALL`或扫描分区表时常常会发生这种情况。就像这些节点可以被用在任何其他计划中一样,它们可以被用在并行计划中。不过,在并行计划中,规划器使用的是`Parallel Append`节点。
当一个`Append`节点被用在并行计划中时,每个进程将按照子计划出现的顺序执行子计划,这样所有的参与进程会合作执行第一个子计划直到它被完成,然后同时移动到第二个计划。而在使用`Parallel Append`时,执行器将把它的子计划尽可能均匀地散布在参与进程中,这样多个子计划会被同时执行。这避免了竞争,也避免了子计划在那些不执行它的进程中产生启动代价。
此外,和常规的`Append`节点不同(在并行计划中使用时仅有部分子计划),Parallel Append`节点既可以有部分子计划也可以有非部分子计划。非部分子计划将仅被单个进程扫描,因为扫描它们不止一次会产生重复的结果。因此涉及到追加多个结果集的计划即使在没有有效的部分计划可用时,也能实现粗粒度的并行。例如,考虑一个针对分区表的查询,它只能通过使用一个不支持并行扫描的索引来实现。规划器可能会选择常规`Index Scan`计划的`Parallel Append。每个索引扫描必须被单一的进程执行完,但不同的扫描可以由不同的进程同时执行。
enable_parallel_append 可以被用来禁用这种特性。
4.2.3.5. 并行计划小贴士
如果我们想要一个查询能产生并行计划但事实上又没有产生,可以尝试减小 parallel_setup_cost 或者 parallel_tuple_cost。当然,这个计划可能比规划器优先产生的顺序计划还要慢,但也不总是如此。如果将这些设置为很小的值(例如把它们设置为零)也不能得到并行计划,那就可能是有某种原因导致查询规划器无法为你的查询产生并行计划。可能的原因可见 第 15.2 节 和 第 15.4 节。
在执行一个并行计划时,可以用`EXPLAIN (ANALYZE,VERBOSE)`来显示每个计划节点在每个工作者上的统计信息。这些信息有助于确定是否所有的工作被均匀地分发到所有计划节点以及从总体上理解计划的性能特点。
5. 事务(参考Sql命令)
5.1. ABORT — 中止当前事务
5.1.2. 描述
ABORT`回滚当前事务并且导致由该事务所作的所有更新被丢弃。这个命令的行为与标准SQL命令 `ROLLBACK 的行为一样,并且只是为了历史原因存在。
5.2. BEGIN — 开始一个事务块
5.2.1. 大纲
BEGIN [ WORK | TRANSACTION ] [ transaction_mode [, ...] ]
其中 transaction_mode 是以下之一:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
READ WRITE | READ ONLY
[ NOT ] DEFERRABLE5.2.2. 描述
BEGIN`开始一个事务块,也就是说所有 `BEGIN`命令之后的所有语句将被在一个 事务中执行,直到给出一个显式的 `COMMIT 或者 ROLLBACK。 默认情况下(没有`BEGIN`), IvorySQL在 “自动提交”模式中执行事务,也就是说每个语句都 在自己的事务中执行并且在语句结束时隐式地执行一次提交(如果执 行成功,否则会完成一次回滚)。
在一个事务块内的语句会执行得更快,因为事务的开始/提交也要求可观 的 CPU 和磁盘活动。在进行多个相关更改时,在一个事务内执行多个语 句也有助于保证一致性:在所有相关更新还没有完成之前,其他会话将不 能看到中间状态。
如果指定了隔离级别、读/写模式或者延迟模式,新事务也会有那些特性, 就像执行了 SET TRANSACTION一样。
5.2.4. 注解
START TRANSACTION具有和`BEGIN` 相同的功能。
在已经在一个事务块中时发出`BEGIN`将惹出一个警告 消息。事务状态不会被影响。要在一个事务块中嵌套事务,可以使用保 存点(见 SAVEPOINT)。
由于向后兼容的原因,连续的 transaction_modes 之间的逗号可以被省略。
5.2.6. 兼容性
BEGIN 是一种 IvorySQL语言扩展。它等效于 SQL 标准的命令 START TRANSACTION,它的参考页 包含额外的兼容性信息。
DEFERRABLE transaction_mode 是一种IvorySQL语言扩展。
附带地,BEGIN 关键词被用于嵌入式 SQL 中的一种 不同目的。在移植数据库应用时,我们建议小心对待事务语义。
5.3. COMMIT — 提交当前事务
5.3.2. 参数
WORKTRANSACTION-
可选的关键词。它们没有效果。
AND CHAIN-
如果指定了
AND CHAIN,则立即启动与刚刚完成的事务具有相同事务特征(参见 SET TRANSACTION)的新事务。 否则,没有新事务被启动。
5.4. COMMIT PREPARED — 提交一个早前为两阶段提交预备的事务
5.4.4. 注解
要提交一个预备的事务,你必须是原先执行该事务的同一用户或者超级用户。 但是不需要处于执行该事务的同一会话中。
这个命令不能在一个事务块中执行。该预备事务将被立刻提交。
pg_prepared_xacts 系统视图中列出了所有当前可用的预备事务。
5.5. END - 提交当前事务
5.5.2. 描述
END`提交当前事务。 所有该事务做的更改便得对他人可见并且被保证发生崩溃时仍然是持久的。 这个命令是一种IvorySQL扩展,它等效于 `COMMIT。
5.5.3. 参数
WORKTRANSACTION-
可选关键词,它们没有效果。
AND CHAIN-
如果规定了`AND CHAIN`,则立即启动与刚完成事务具有相同事务特征(参见 SET TRANSACTION)的新事务。否则,没有新事务被启动。
5.5.6. 兼容性
END 是一种IvorySQL扩展,它提供和 COMMIT等效的功能,后者在 SQL 标准中指定。
5.6. PREPARE TRANSACTION — 为两阶段提交准备当前事务
5.6.2. 描述
PREPARE TRANSACTION 为两阶段提交准备 当前事务。在这个命令之后,该事务不再与当前会话关联。相反,它的状态 被完全存储在磁盘上,并且有很高的可能性它会被提交成功(即便在请求提 交前发生数据库崩溃)。
一旦被准备好,事务稍后就可以分别用 COMMIT PREPARED或者 ROLLBACK PREPARED提交或者回滚。 可以从任何会话而不仅仅是执行原始事务的会话中发出这些命令。
从发出命令的会话的角度来看,PREPARE TRANSACTION`不像 `ROLLBACK 命令: 在执行它之后,就没有活跃的当前事务,并且该预备事务的效果也不再可见( 如果该事务被提交,效果将重新变得可见)。
如果由于任何原因 PREPARE TRANSACTION 命令失败,它会变成一个 ROLLBACK :当前事务会被取消。
5.6.3. 参数
transaction_id-
一个任意的事务标识符,
COMMIT PREPARED或者`ROLLBACK PREPARED` 以后将用这个标识符来标识这个事务。该标识符必须写成一个字符串,并且长度必须小于 200 字节。它也不能与任何当前已经准备好的事务的标识符相同。
5.6.4. 注解
PREPARE TRANSACTION 并不是设计为在应用或者交互式 会话中使用。它的目的是允许一个外部事务管理器在多个数据库或者其他事务性 来源之间执行原子的全局事务。除非你在编写一个事务管理器,否则你可能不会 用到`PREPARE TRANSACTION`。
这个命令必须在一个事务块中使用。事务块用 BEGIN开始。
当前在已经执行过任何涉及到临时表或者会话的临时命名空间、创建带 WITH HOLD 的游标或者执行 LISTEN、UNLISTEN 或 NOTIFY 的 事务中,不允许`PREPARE`该事务。这些特性与当前会话 绑定得太过紧密,所以对一个要被准备的事务来说没有什么用处。
如果用 SET(不带 LOCAL 选项)修改过事务的 任何运行时参数,这些效果会持续到 PREPARE TRANSACTION 之后,并且将不会被后续的任何 COMMIT PREPARED 或 ROLLBACK PREPARED 所影响。因此,在这一 方面`PREPARE TRANSACTION` 的行为更像 COMMIT 而不是`ROLLBACK`。
所有当前可用的准备好事务被列在 pg_prepared_xacts系统视图中。
5.6.5. 小心
让一个事务处于准备好状态太久是不明智的。这将会干扰 VACUUM 回收存储的能力,并且在极限情况下可能导致 数据库关闭以阻止事务 ID 回卷(见 第 25.1.5 节)。还要记住,该事务会继续持有 它已经持有的锁。该特性的设计用法是,只要一个外部事务管理器已经验证 其他数据库也准备好了要提交,一个准备好的事务将被正常地提交或者回滚。
如果没有建立一个外部事务管理器来跟踪准备好的事务并且确保它们被迅速地 结束,最好禁用准备好事务特性(设置 max_prepared_transactions 为零)。这将防止意外 地创建准备好事务,不然该事务有可能被忘记并且最终导致问题。
5.7. ROLLBACK — 中止当前事务
5.7.3. 参数
WORKTRANSACTION-
可选关键词,没有效果。
AND CHAIN-
如果指定了
AND CHAIN,则立即启动与刚刚完成事务具有相同事务特征(参见 SET TRANSACTION)的新事务。 否则,不会启动任何新事务。
5.8. ROLLBACK PREPARED — 取消一个之前为两阶段提交准备好的事务
5.8.4. 注解
要回滚一个准备好的事务,你必须是原先执行该事务的同一个用户或者 是一个超级用户。但是你必须处在执行该事务的同一个会话中。
这个命令不能在一个事务块内被执行。准备好的事务会被立刻回滚。
pg_prepared_xacts 系统视图中列出了当前可用的所有准备好的事务。
5.9. SAVEPOINT — 在当前事务中定义一个新的保存点
5.9.4. 注解
使用 ROLLBACK TO回滚到一个保存点。 使用 RELEASE SAVEPOINT销毁一个保存点, 但保持在它被建立之后执行的命令的效果。
保存点只能在一个事务块内建立。可以在一个事务内定义多个保存点。
5.9.5. 示例
要建立一个保存点并且后来撤销在它建立之后执行的所有命令的效果:
BEGIN;
INSERT INTO table1 VALUES (1);
SAVEPOINT my_savepoint;
INSERT INTO table1 VALUES (2);
ROLLBACK TO SAVEPOINT my_savepoint;
INSERT INTO table1 VALUES (3);
COMMIT;上面的事务将插入值 1 和 3,但不会插入 2。
要建立并且稍后销毁一个保存点:
BEGIN;
INSERT INTO table1 VALUES (3);
SAVEPOINT my_savepoint;
INSERT INTO table1 VALUES (4);
RELEASE SAVEPOINT my_savepoint;
COMMIT;上面的事务将插入 3 和 4。
5.10. SET CONSTRAINTS — 为当前事务设置约束检查时机
5.10.2. 描述
SET CONSTRAINTS 设置当前事务内约束检查的行为。IMMEDIATE 约束在每个语句结束时被检查。 DEFERRED 约束直到事务提交时才被检查。每个约束都有 自己的 IMMEDIATE 或 DEFERRED 模式。
在创建时,一个约束会被给定三种特性之一: DEFERRABLE INITIALLY DEFERRED、 DEFERRABLE INITIALLY IMMEDIATE 或者 NOT DEFERRABLE 。第三类总是 IMMEDIATE 并且不会受到 SET CONSTRAINTS 命令的影响。前两类在每个 事务开始时都处于指定的模式,但是它们的行为可以在一个事务内用 SET CONSTRAINTS 更改。
带有一个约束名称列表的 SET CONSTRAINTS 只更改那些约束(都必须是可延迟的)的模式。每一个约束名称都可以是 模式限定的。如果没有指定模式名称,则当前的模式搜索路径将被用来寻找 第一个匹配的名称。SET CONSTRAINTS ALL 更改所有可延迟约束的模式。
当 SET CONSTRAINTS 把一个约束的模式从 DEFERRED 改成 IMMEDIATE 时, 新模式会有追溯效果:任何还没有解决的数据修改(本来会在事务结束时 被检查)会转而在 SET CONSTRAINTS 命令 的执行期间被检查。如果任何这种约束被违背, SET CONSTRAINTS 将会失败(并且不会改 变该约束模式)。这样,SET CONSTRAINTS 可以被用来在一个事务中的特定点强制进 行约束检查。
当前,只有 UNIQUE、PRIMARY KEY、 REFERENCES(外键)以及 EXCLUDE 约束受到这个设置的影响。 NOT NULL 以及 CHECK 约束总是在一行 被插入或修改时立即检查(不是在语句结束时)。 没有被声明为 DEFERRABLE 的唯一和排除约束也会被 立刻检查。
被声明为“约束触发器”的触发器的引发也受到这个设置 的控制 — 它们会在相关约束被检查的同时被引发。
5.11. SET TRANSACTION — 设置当前事务的特性
5.11.1. 大纲
SET TRANSACTION transaction_mode [, ...]
SET TRANSACTION SNAPSHOT snapshot_id
SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, ...]
其中 transaction_mode 是下列之一:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
READ WRITE | READ ONLY
[ NOT ] DEFERRABLE5.11.2. 描述
SET TRANSACTION 命令设置当前 会话的特性。SET SESSION CHARACTERISTICS 设置一个会话后续事务的默认 事务特性。在个体事务中可以用 `SET TRANSACTION`覆盖这些默认值。
可用的事务特性是事务隔离级别、事务访问模式(读/写或只读)以及 可延迟模式。此外,可以选择一个快照,不过只能用于当前事务而不能 作为会话默认值。
一个事务的隔离级别决定当其他事务并行运行时该事务能看见什么数据:
READ COMMITTED-
一个语句只能看到在它开始前提交的行。这是默认值。
REPEATABLE READ-
当前事务的所有语句只能看到这个事务中执行的第一个查询或者数据修改语句之前提交的行。
SERIALIZABLE-
当前事务的所有语句只能看到这个事务中执行的第一个查询或者数据修改语句之前提交的行。如果并发的可序列化事务间的读写模式可能导致一种那些事务串行(一次一个)执行时不可能出现的情况,其中之一将会被回滚并且得到一个 `serialization_failure`错误。
SQL 标准定义了一种额外的级别:READ UNCOMMITTED。在IvorySQL中 READ UNCOMMITTED 被视作 READ COMMITTED。
一个事务执行了第一个查询或者数据修改语句( SELECT、 INSERT、DELETE、 UPDATE、FETCH 或 COPY)之后就无法更改事务隔离级别。 更多有关事务隔离级别和并发控制的信息可见 第 13 章。
事务的访问模式决定该事务是否为读/写或者只读。读/写是默认值。 当一个事务为只读时,如果SQL命令 INSERT、UPDATE、 DELETE 和 COPY FROM 要写的表不是一个临时表,则它们不被允许。不允许 CREATE、ALTER`以及 `DROP 命令。不允许 COMMENT、 GRANT、REVOKE、 TRUNCATE。如果 EXPLAIN ANALYZE 和`EXECUTE` 要执行的命令是上述命令之一,则它们也不被允许。这是一种高层的只读概念,它不能阻止所有对磁盘的写入。
只有事务也是 SERIALIZABLE 以及 READ ONLY 时,DEFERRABLE 事务属性才会有效。当一个事务的所有这三个属性都被选择时,该事务在第一次获取其快照时可能会阻塞,在那之后它运行时就不会有 SERIALIZABLE 事务的开销并且不会有任何牺牲或者被一次序列化失败取消的风险。这种模式很适合于长时间运行的报表或者备份。
SET TRANSACTION SNAPSHOT 命令允许新的事务使用与一个现有事务相同的 快照 运行。已经存在的事务必须已经把它的快照用 pg_export_snapshot 函数(见 第 9.27.5 节)导出。该函数会返回一个快照标识符,SET TRANSACTION SNAPSHOT 需要被给定一个快照标识符来指定要导入的快照。在这个命令中该标识符必须被写成一个字符串,例如 '000003A1-1'。 SET TRANSACTION SNAPSHOT 只能在一个事务的开始执行,并且要在该事务的第一个查询或者数据修改语句( SELECT、 INSERT、DELETE、 UPDATE、FETCH`或 `COPY)之前执行。此外,该事务必须已经被设置为`SERIALIZABLE` 或者 REPEATABLE READ 隔离级别(否则,该快照将被立刻抛弃,因为 READ COMMITTED 模式会为每一个命令取一个新快照)。如果导入事务使用了`SERIALIZABLE` 隔离级别,那么导入快照的事务必须也使用该隔离级别。还有,一个非只读可序列化事务不能导入来自只读事务的快照。
5.11.3. 注解
如果执行 SET TRANSACTION 之前没有 START TRANSACTION 或者 BEGIN,它会发出一个警告并且不会有任何效果。
可以通过在 BEGIN 或者 START TRANSACTION 中指定想要的 transaction_modes 来省掉 SET TRANSACTION。但是在 SET TRANSACTION SNAPSHOT 中该选项不可用。
会话默认的事务模式也可以通过配置参数 default_transaction_isolation、 default_transaction_read_only 和 default_transaction_deferrable 来设置或检查(实际上 SET SESSION CHARACTERISTICS`只是用 `SET 设置这些变量的等效体)。这意味着可以通过配置文件、 ALTER DATABASE 等方式设置默认值。详见 第 20 章。
当前事务的模式可以类似的通过配置参数 transaction_isolation、 transaction_read_only、和 transaction_deferrable 来设置或检查。设置这其中一个参数的作用与相应的 SET TRANSACTION 选项相同,在它何时可以完成方面,也有相同的限制。但是,这些参数不能在配置文件中设置,或者从活动SQL以外的任何来源来设置。
5.11.4. 示例
要用一个已经存在的事务的同一快照开始一个新事务,首先要从该现有 事务导出快照。这将会返回快照标识符,例如:
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SELECT pg_export_snapshot();
pg_export_snapshot
---------------------
00000003-0000001B-1
(1 row)然后在一个新开始的事务的开头把该快照标识符用在一个 SET TRANSACTION SNAPSHOT 命令中:
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET TRANSACTION SNAPSHOT '00000003-0000001B-1';5.11.5. 兼容性
SQL标准中定义了这些命令,不过 DEFERRABLE 事务模式和 SET TRANSACTION SNAPSHOT 形式除外,这两者是 IvorySQL扩展。
SERIALIZABLE 是标准中默认的事务隔离级别。在 IvorySQL中默认值是普通的 READ COMMITTED,但是你可以按上述的方式更改。
在SQL标准中,可以用这些命令设置一个其他的事务特性:诊断区域 的尺寸。这个概念与嵌入式SQL有关,并且因此没有在IvorySQL服务器中实现。
SQL 标准要求连续的 transaction_modes 之间有逗号,但是出于历史原因IvorySQL允许省略逗号。
5.12. START TRANSACTION — 开始一个事务块
5.12.1. 大纲
START TRANSACTION [ transaction_mode [, ...] ]
其中 transaction_mode 是下列之一:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
READ WRITE | READ ONLY
[ NOT ] DEFERRABLE5.12.2. 描述
这个命令开始一个新的事务块。如果指定了隔离级别、读写模式 或者可延迟模式,新的事务将会具有这些特性,就像执行了 SET TRANSACTION一样。这和 BEGIN命令一样。
5.12.3. 参数
这些参数对于这个语句的含义可参考 SET TRANSACTION。
6. Sql参考(第 4 章 SQL语法)
6.1. 词法结构
SQL输入由一个 命令 序列组成。一个命令由一个 记号 的序列构成,并由一个分号(“;”)终结。输入流的末端也会标志一个命令的结束。具体哪些记号是合法的与具体命令的语法有关。
一个记号可以是一个 关键词、一个 标识符、一个 带引号的标识符、一个 literal(或常量)或者一个特殊字符符号。记号通常以空白(空格、制表符、新行)来分隔,但在无歧义时并不强制要求如此(唯一的例子是一个特殊字符紧挨着其他记号)。
例如,下面是一个(语法上)合法的SQL输入:
SELECT * FROM MY_TABLE;
UPDATE MY_TABLE SET A = 5;
INSERT INTO MY_TABLE VALUES (3, 'hi there');这是一个由三个命令组成的序列,每一行一个命令(尽管这不是必须地,在同一行中可以有超过一个命令,而且命令还可以被跨行分割)。
另外,注释 也可以出现在SQL输入中。它们不是记号,它们和空白完全一样。
根据标识命令、操作符、参数的记号不同,SQL的语法不很一致。最前面的一些记号通常是命令名,因此在上面的例子中我们通常会说一个“SELECT”、一个“UPDATE”和一个“INSERT”命令。但是例如 UPDATE 命令总是要求一个 SET 记号出现在一个特定位置,而 INSERT 则要求一个 VALUES 来完成命令。每个命令的精确语法规则在 第 VI 部分 中介绍。
6.1.1. 标识符和关键词
上例中的 SELECT、UPDATE 或 VALUES 记号是 关键词 的例子,即SQL语言中具有特定意义的词。记号 MY_TABLE 和 A 则是 标识符 的例子。它们标识表、列或者其他数据库对象的名字,取决于使用它们的命令。因此它们有时也被简称为“名字”。关键词和标识符具有相同的词法结构,这意味着我们无法在没有语言知识的前提下区分一个标识符和关键词。一个关键词的完整列表可以在 附录 C中找到。
SQL标识符和关键词必须以一个字母(a-z,也可以是带变音符的字母和非拉丁字母)或一个下划线( _ )开始。后续字符可以是字母、下划线( _)、数字(0-9)或美元符号($)。注意根据SQL标准的字母规定,美元符号是不允许出现在标识符中的,因此它们的使用可能会降低应用的可移植性。SQL标准不会定义包含数字或者以下划线开头或结尾的关键词,因此这种形式的标识符不会与未来可能的标准扩展冲突 。
系统中一个标识符的长度不能超过 NAMEDATALEN-1 字节,在命令中可以写超过此长度的标识符,但是它们会被截断。默认情况下,NAMEDATALEN 的值为64,因此标识符的长度上限为63字节。如果这个限制有问题,可以在 src/include/pg_config_manual.h 中修改 NAMEDATALEN 常量。
关键词和不被引号修饰的标识符是大小写不敏感的。因此:
UPDATE MY_TABLE SET A = 5;可以等价地写成:
uPDaTE my_TabLE SeT a = 5;一个常见的习惯是将关键词写成大写,而名称写成小写,例如:
UPDATE my_table SET a = 5;这里还有第二种形式的标识符:受限标识符*或*被引号修饰的标识符。它是由双引号(")包围的一个任意字符序列。一个受限标识符总是一个标识符而不会是一个关键字。因此 "select" 可以用于引用一个名为“select”的列或者表,而一个没有引号修饰的 select 则会被当作一个关键词,从而在本应使用表或列名的地方引起解析错误。在上例中使用受限标识符的例子如下:
UPDATE "my_table" SET "a" = 5;受限标识符可以包含任何字符,除了代码为0的字符(如果要包含一个双引号,则写两个双引号)。这使得可以构建原本不被允许的表或列的名称,例如包含空格或花号的名字。但是长度限制依然有效。
引用标识符也使其区分大小写,而未引用的名称总是折叠成小写。例如,标识符 FOO、foo 和 "foo" 在IvorySQL中被认为是相同的,但是 "Foo" 和 "FOO" 与这三个不同,并且彼此不同。(在IvorySQL中,将不带引号的名称折叠为小写与SQL标准不兼容,SQL标准规定不带引号的名称应折叠为大写。因此,根据标准,foo 应等同于 "FOO" 而不是 "foo"。如果您想编写可移植应用程序,建议您始终引用某个特定的名称,或者永远不要引用它。)
一种受限标识符的变体允许包括转义的用代码点标识的Unicode字符。这种变体以 U& (大写或小写U跟上一个花号)开始,后面紧跟双引号修饰的名称,两者之间没有任何空白,如 U&"foo"(注意这里与操作符 & 似乎有一些混淆,但是在`&`操作符周围使用空白避免了这个问题) 。在引号内,Unicode字符可以以转义的形式指定:反斜线接上4位16进制代码点号码或者反斜线和加号接上6位16进制代码点号码。例如,标识符 "data" 可以写成:
U&"d\0061t\+000061"下面的例子用斯拉夫语字母写出了俄语单词 “slon”(大象):
U&"\0441\043B\043E\043D"如果希望使用其他转义字符来代替反斜线,可以在字符串后使用 UESCAPE 子句,例如:
U&"d!0061t!+000061" UESCAPE '!'转义字符可以是除了16进制位、加号、单引号、双引号、空白字符之外的任意单个字符。请注意,转义字符在 UESCAPE 之后用单引号而不是双引号书写。
为了在标识符中包括转义字符本身,将其写两次即可。
4位或6位转义形式都可以被用来定义UTF-16代理对来组成代码点大于U+FFFF的字符,尽管6位形式的存在使得这种做法变得不必要(代理对并不被直接存储,而是绑定成一个单独的代码点)。
如果服务器编码不是UTF-8,则由其中一个转义序列标识的Unicode代码点转换为实际的服务器编码;如果不可能,则报告错误。
6.1.2. 常量
在IvorySQL中有三种 隐式类型常量:字符串、位串和数字。常量也可以被指定显式类型,这可以使得它被更精确地展示以及更有效地处理。这些选择将会在后续小节中讨论。
6.1.2.1. 字符串常量
在SQL中,一个字符串常量是一个由单引号( ' )包围的任意字符序列,例如 'This is a string'。为了在一个字符串中包括一个单引号,可以写两个相连的单引号,例如 'Dianne''s horse'。注意这和一个双引号( " )不同。
两个只由空白及至少一个新行分隔的字符串常量会被连接在一起,并且将作为一个写在一起的字符串常量来对待。例如:
SELECT 'foo'
'bar';等同于:
SELECT 'foobar';但是:
SELECT 'foo' 'bar';则不是合法的语法(这种有些奇怪的行为是SQL指定的,IvorySQL遵循了该标准)。
6.1.2.2. C风格转义的字符串常量
IvorySQL也接受“转义”字符串常量,这也是SQL标准的一个扩展。一个转义字符串常量可以通过在开单引号前面写一个字母 E(大写或小写形式)来指定,例如 E’foo'(当一个转义字符串常量跨行时,只在第一个开引号之前写 E )。在一个转义字符串内部,一个反斜线字符( \ )会开始一个 C 风格的 反斜线转义 序列,在其中反斜线和后续字符的组合表示一个特殊的字节值(如 表 4.1 中所示)。
表 4.1. 反斜线转义序列
反斜线转义序列 |
解释 |
|
退格 |
|
换页 |
|
换行 |
|
回车 |
|
制表符 |
|
八进制字节值 |
|
十六进制字节值 |
|
16 或 32-位十六进制 Unicode 字符值 |
跟随在一个反斜线后面的任何其他字符被当做其字面意思。因此,要包括一个反斜线字符,请写两个反斜线( \\ )。在一个转义字符串中包括一个单引号除了普通方法 '' 之外,还可以写成 \' 。
你要负责保证你创建的字节序列由服务器字符集编码中合法的字符组成,特别是在使用八进制或十六进制转义时。一个有用的替代方法是使用Unicode转义或替代的Unicode转义语法,如 第 4.1.2.3 节 中所述;然后服务器将检查字符转换是否可行。
6.1.2.3. 带有 Unicode 转义的字符串常量
IvorySQL也支持另一种类型的字符串转义语法,它允许用代码点指定任意 Unicode 字符。一个 Unicode 转义字符串常量开始于 U& (大写或小写形式的字母 U,后跟花号),后面紧跟着开引号,之间没有任何空白,例如 U&'foo' (注意这产生了与操作符 & 的混淆。在操作符周围使用空白来避免这个问题)。在引号内,Unicode 字符可以通过写一个后跟 4 位十六进制代码点编号或者一个前面有加号的 6 位十六进制代码点编号的反斜线来指定。例如,字符串 'data' 可以被写为
U&'d\0061t\+000061'下面的例子用斯拉夫字母写出了俄语的单词“slon”(大象):
U&'\0441\043B\043E\043D'如果想要一个不是反斜线的转义字符,可以在字符串之后使用 UESCAPE 子句来指定,例如:
U&'d!0061t!+000061' UESCAPE '!'转义字符可以是出一个十六进制位、加号、单引号、双引号或空白字符之外的任何单一字符。
要在一个字符串中包括一个表示其字面意思的转义字符,把它写两次。
4位或6位转义形式可用于指定UTF-16代理项对,以组成代码点大于U+FFFF的字符,尽管从技术上讲,6位形式的可用性使得这是不必要的(代理项对不是直接存储的,而是合并到单个代码点中。)
如果服务器编码不是 UTF-8,则由这些转义序列之一标识的 Unicode 代码点将转换为实际的服务器编码; 如果不可能,则会报告错误。
此外,字符串常量的 Unicode 转义语法仅在配置参数 standard_conforming_strings 开启时才有效。 这是因为否则这种语法可能会混淆解析 SQL 语句的客户端,可能导致 SQL 注入和类似的安全问题。 如果该参数设置为 off,则此语法将被拒绝并显示错误消息。
6.1.2.4. 美元引用的字符串常量
虽然用于指定字符串常量的标准语法通常都很方便,但是当字符串中包含了很多单引号或反斜线时很难理解它,因为每一个都需要被双写。要在这种情形下允许可读性更好的查询,IvorySQL提供了另一种被称为“美元引用”的方式来书写字符串常量。一个美元引用的字符串常量由一个美元符号( $ )、一个可选的另个或更多字符的“标签”、另一个美元符号、一个构成字符串内容的任意字符序列、一个美元符号、开始这个美元引用的相同标签和一个美元符号组成。例如,这里有两种不同的方法使用美元引用指定字符串“Dianne’s horse”:
$$Dianne's horse$$
$SomeTag$Dianne's horse$SomeTag$注意在美元引用字符串中,单引号可以在不被转义的情况下使用。事实上,在一个美元引用字符串中不需要对字符进行转义:字符串内容总是按其字面意思写出。反斜线不是特殊的,并且美元符号也不是特殊的,除非它们是匹配开标签的一个序列的一部分。
可以通过在每一个嵌套级别上选择不同的标签来嵌套美元引用字符串常量。这最常被用在编写函数定义上。例如:
$function$
BEGIN
RETURN ($1 ~ $q$[\t\r\n\v\\]$q$);
END;
$function$这里,序列 $q$[\t\r\n\v\\]$q$ 表示一个美元引用的文字串 [\t\r\n\v\\],当该函数体被IvorySQL执行时它将被识别。但是因为该序列不匹配外层的美元引用的定界符 $function$,它只是一些在外层字符串所关注的常量中的字符而已。
一个美元引用字符串的标签(如果有)遵循一个未被引用标识符的相同规则,除了它不能包含一个美元符号之外。标签是大小写敏感的,因此 $tag$String content$tag$ 是正确的,但是 $TAG$String content$tag$ 不正确。
一个跟着一个关键词或标识符的美元引用字符串必须用空白与之分隔开,否则美元引用定界符可能会被作为前面标识符的一部分。
美元引用不是SQL标准的一部分,但是在书写复杂字符串文字方面,它常常是一种比兼容标准的单引号语法更方便的方法。当要表示的字符串常量位于其他常量中时它特别有用,这种情况常常在过程函数定义中出现。如果用单引号语法,上一个例子中的每个反斜线将必须被写成四个反斜线,这在解析原始字符串常量时会被缩减到两个反斜线,并且接着在函数执行期间重新解析内层字符串常量时变成一个。
6.1.2.5. 位串常量
位串常量看起来像常规字符串常量在开引号之前(中间无空白)加了一个 B(大写或小写形式),例如 B'1001' 。位串常量中允许的字符只有 0 和 1 。
作为一种选择,位串常量可以用十六进制记号法指定,使用一个前导 X(大写或小写形式),例如 X'1FF'。这种记号法等价于一个用四个二进制位取代每个十六进制位的位串常量。
两种形式的位串常量可以以常规字符串常量相同的方式跨行继续。美元引用不能被用在位串常量中。
6.1.2.6. 数字常量
在这些一般形式中可以接受数字常量:
digits
digits.[digits][e[+-]digits]
[digits].digits[e[+-]digits]
digitse[+-]digits其中 digits 是一个或多个十进制数字(0 到 9)。如果使用了小数点,在小数点前面或后面必须至少有一个数字。如果存在一个指数标记( e ),在其后必须跟着至少一个数字。在该常量中不能嵌入任何空白或其他字符。注意任何前导的加号或减号并不实际被考虑为常量的一部分,它是一个应用到该常量的操作符。
这些是合法数字常量的例子:
42
3.5
4.
.001
5e2
1.925e-3如果一个不包含小数点和指数的数字常量的值适合类型 integer (32 位),它首先被假定为类型 integer 。否则如果它的值适合类型 bigint (64 位),它被假定为类型 bigint 。再否则它会被取做类型 numeric 。包含小数点和/或指数的常量总是首先被假定为类型 numeric 。
一个数字常量初始指派的数据类型只是类型转换算法的一个开始点。在大部分情况中,常量将被根据上下文自动被强制到最合适的类型。必要时,你可以通过造型它来强制一个数字值被解释为一种指定数据类型。例如,你可以这样强制一个数字值被当做类型 real ( float4 ):
REAL '1.23' -- string style
1.23::REAL -- IvorySQL (historical) style这些实际上只是接下来要讨论的一般造型记号的特例。
6.1.2.7. 其他类型的常量
一种任意类型的一个常量可以使用下列记号中的任意一种输入:
type 'string'
'string'::type
CAST ( 'string' AS type )字符串常量的文本被传递到名为 type 的类型的输入转换例程中。其结果是指定类型的一个常量。如果对该常量的类型没有歧义(例如,当它被直接指派给一个表列时),显式类型造型可以被忽略,在那种情况下它会被自动强制。
字符串常量可以使用常规 SQL 记号或美元引用书写。
也可以使用一个类似函数的语法来指定一个类型强制:
typename ( 'string' )但是并非所有类型名都可以用在这种方法中,详见 第 4.2.9 节。
如 第 4.2.9 节 中讨论的,::、CAST() 以及函数调用语法也可以被用来指定任意表达式的运行时类型转换。要避免语法歧义,type 'string' 语法只能被用来指定简单文字常量的类型。type 'string' 语法上的另一个限制是它无法对数组类型工作,指定一个数组常量的类型可使用 :: 或 CAST() 。
CAST() 语法符合SQL。type 'string' 语法是该标准的一般化:SQL指定这种语法只用于一些数据类型,但是IvorySQL允许它用于所有类型。带有 :: 的语法是IvorySQL的历史用法,就像函数调用语法一样。
6.1.3. 操作符
一个操作符名是最多 NAMEDATALEN -1(默认为 63)的一个字符序列,其中的字符来自下面的列表:
\+ - * / < > = ~ ! @ # % ^ & | ` ?不过,在操作符名上有一些限制:
-
--和/*不能在一个操作符名的任何地方出现,因为它们将被作为一段注释的开始。 -
一个多字符操作符名不能以
+或-结尾,除非该名称也至少包含这些字符中的一个:~ ! @ # % ^ & | ` ?
例如,@- 是一个被允许的操作符名,但 *- 不是。这些限制允许IvorySQL解析 SQL 兼容的查询而不需要在记号之间有空格。
当使用非 SQL 标准的操作符名时,你通常需要用空格分隔相邻的操作符来避免歧义。例如,如果你定义了一个名为 @ 的前缀操作符,你不能写 X*@Y,你必须写 X* @Y 来确保IvorySQL把它读作两个操作符名而不是一个。
6.1.4. 特殊字符
一些不是数字字母的字符有一种不同于作为操作符的特殊含义。这些字符的详细用法可以在描述相应语法元素的地方找到。这一节只是为了告知它们的存在以及总结这些字符的目的。
-
跟随在一个美元符号(
$)后面的数字被用来表示在一个函数定义或一个预备语句中的位置参数。在其他上下文中该美元符号可以作为一个标识符或者一个美元引用字符串常量的一部分。 -
圆括号(
())具有它们通常的含义,用来分组表达式并且强制优先。在某些情况中,圆括号被要求作为一个特定 SQL 命令的固定语法的一部分。 -
方括号(
[])被用来选择一个数组中的元素。更多关于数组的信息见 第 8.15 节。 -
逗号(
,)被用在某些语法结构中来分割一个列表的元素。 -
分号(
;)结束一个 SQL 命令。它不能出现在一个命令中间的任何位置,除了在一个字符串常量中或者一个被引用的标识符中。 -
冒号(
:)被用来从数组中选择“切片”(见 第 8.15 节)。在某些 SQL 的“方言”(例如嵌入式 SQL)中,冒号被用来作为变量名的前缀。 -
星号(
*)被用在某些上下文中标记一个表的所有域或者组合值。当它被用作一个聚集函数的参数时,它还有一种特殊的含义,即该聚集不要求任何显式参数。 -
句点(
.)被用在数字常量中,并且被用来分割模式、表和列名。
6.1.5. 注释
一段注释是以双横杠开始并且延伸到行结尾的一个字符序列,例如:
-- This is a standard SQL comment另外,也可以使用 C 风格注释块:
/* multiline comment
* with nesting: /* nested block comment */
*/这里该注释开始于 / 并且延伸到匹配出现的 /。这些注释块可按照 SQL 标准中指定的方式嵌套,但和 C 中不同。这样我们可以注释掉一大段可能包含注释块的代码。
在进一步的语法分析前,注释会被从输入流中被移除并且实际被替换为空白。
6.1.5.1. 操作符优先级
表 4.2 显示了IvorySQL中操作符的优先级和结合性。大部分操作符具有相同的优先并且是左结合的。操作符的优先级和结合性被硬写在解析器中。 如果您希望以不同于优先级规则所暗示的方式解析具有多个运算符的表达式,请添加括号。
表 4.2. 操作符优先级(从高到低)
操作符/元素 |
结合性 |
描述 |
|
左 |
表/列名分隔符 |
|
左 |
IvorySQL-风格的类型转换 |
|
左 |
数组元素选择 |
|
右 |
一元加、一元减 |
|
左 |
指数 |
|
左 |
乘、除、模 |
|
左 |
加、减 |
(任意其他操作符) |
左 |
所有其他本地以及用户定义的操作符 |
|
范围包含、集合成员关系、字符串匹配 |
|
|
比较操作符 |
|
|
|
|
|
右 |
逻辑否定 |
|
左 |
逻辑合取 |
|
左 |
逻辑析取 |
注意该操作符有限规则也适用于与上述内建操作符具有相同名称的用户定义的操作符。例如,如果你为某种自定义数据类型定义了一个“”操作符,它将具有和内建的“”操作符相同的优先级,不管你的操作符要做什么。
当一个模式限定的操作符名被用在`OPERATOR`语法中时,如下面的例子:
SELECT 3 OPERATOR(pg_catalog.+) 4;`OPERATOR`结构被用来为“任意其他操作符”获得 表 4.2 中默认的优先级。不管出现在`OPERATOR()`中的是哪个指定操作符,这都是真的。
6.2. 值表达式
值表达式被用于各种各样的环境中,例如在 SELECT 命令的目标列表中、作为 INSERT 或 UPDATE 中的新列值或者若干命令中的搜索条件。为了区别于一个表表达式(是一个表)的结果,一个值表达式的结果有时候被称为一个 标量。值表达式因此也被称为 标量表达式(或者甚至简称为 表达式)。表达式语法允许使用算数、逻辑、集合和其他操作从原始部分计算值。
一个值表达式是下列之一:
-
一个常量或文字值
-
一个列引用
-
在一个函数定义体或预备语句中的一个位置参数引用
-
一个下标表达式
-
一个域选择表达式
-
一个操作符调用
-
一个函数调用
-
一个聚集表达式
-
一个窗口函数调用
-
一个类型转换
-
一个排序规则表达式
-
一个标量子查询
-
一个数组构造器
-
一个行构造器
-
另一个在圆括号(用来分组子表达式以及重载优先级)中的值表达式
在这个列表之外,还有一些结构可以被分类为一个表达式,但是它们不遵循任何一般语法规则。这些通常具有一个函数或操作符的语义并且在 第 9 章 中的合适位置解释。一个例子是 IS NULL 子句。
我们已经在 第 4.1.2 节 中讨论过常量。下面的小节会讨论剩下的选项。
6.2.1. 列引用
一个列可以以下面的形式被引用:
correlation.columnnamecorrelation 是一个表(有可能以一个模式名限定)的名字,或者是在 FROM 子句中为一个表定义的别名。如果列名在当前索引所使用的表中都是唯一的,关联名称和分隔用的句点可以被忽略(另见 第 7 章)。
6.2.2. 位置参数
一个位置参数引用被用来指示一个由 SQL 语句外部提供的值。参数被用于 SQL 函数定义和预备查询中。某些客户端库还支持独立于 SQL 命令字符串来指定数据值,在这种情况中参数被用来引用那些线外数据值。一个参数引用的形式是:
$number例如,考虑一个函数 dept 的定义:
CREATE FUNCTION dept(text) RETURNS dept
AS $$ SELECT * FROM dept WHERE name = $1 $$
LANGUAGE SQL;这里 $1 引用函数被调用时第一个函数参数的值。
6.2.3. 下标
如果一个表达式得到了一个数组类型的值,那么可以抽取出该数组值的一个特定元素:
expression[subscript]或者抽取出多个相邻元素(一个“数组切片”):
expression[lower_subscript:upper_subscript](这里,方括号 [ ] 表示其字面意思)。每一个 下标 自身是一个表达式,它将四舍五入到最接近的整数值。
通常,数组 表达式 必须被加上括号,但是当要被加下标的表达式只是一个列引用或位置参数时,括号可以被忽略。还有,当原始数组是多维时,多个下标可以被连接起来。例如:
mytable.arraycolumn[4]
mytable.two_d_column[17][34]
$1[10:42]
(arrayfunction(a,b))[42]最后一个例子中的圆括号是必需的。详见 第 8.15 节。
6.2.4. 域选择
如果一个表达式得到一个组合类型(行类型)的值,那么可以抽取该行的指定域
expression.fieldname通常行 表达式 必须被加上括号,但是当该表达式是仅从一个表引用或位置参数选择时,圆括号可以被忽略。例如:
mytable.mycolumn
$1.somecolumn
(rowfunction(a,b)).col3(因此,一个被限定的列引用实际上只是域选择语法的一种特例)。一种重要的特例是从一个组合类型的表列中抽取一个域:
(compositecol).somefield
(mytable.compositecol).somefield这里需要圆括号来显示 compositecol 是一个列名而不是一个表名,在第二种情况中则是显示 mytable 是一个表名而不是一个模式名。
你可以通过书写 .* 来请求一个组合值的所有域:
(compositecol).*这种记法的行为根据上下文会有不同,详见 第 8.16.5 节。
6.2.5. 操作符调用
对于一次操作符调用,有两种可能的语法:
|
|
其中 operator 记号遵循 第 4.1.3 节 的语法规则,或者是关键词`AND`、`OR`和`NOT`之一,或者是一个如下形式的受限定操作符名:
OPERATOR(schema.operatorname)哪个特定操作符存在以及它们是一元的还是二元的取决于由系统或用户定义的那些操作符。 第 9 章 描述了内建操作符。
6.2.6. 函数调用
一个函数调用的语法是一个函数的名称(可能受限于一个模式名)后面跟上封闭于圆括号中的参数列表:
function_name ([expression [, expression ... ]] )例如,下面会计算 2 的平方根:
sqrt(2)当在一个某些用户不信任其他用户的数据库中发出查询时,在编写函数调用时应遵守 第 10.3 节 中的安全防范措施。
内建函数的列表在 第 9 章 中。其他函数可以由用户增加。
参数可以有选择地被附加名称。详见 第 4.3 节。
6.2.7. 聚集表达式
一个 聚集表达式 表示在由一个查询选择的行上应用一个聚集函数。一个聚集函数将多个输入减少到一个单一输出值,例如对输入的求和或平均。一个聚集表达式的语法是下列之一:
aggregate_name (expression [ , ... ] [ order_by_clause ] ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name (ALL expression [ , ... ] [ order_by_clause ] ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name (DISTINCT expression [ , ... ] [ order_by_clause ] ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name ( * ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name ( [ expression [ , ... ] ] ) WITHIN GROUP ( order_by_clause ) [ FILTER ( WHERE filter_clause ) ]这里 aggregate_name 是一个之前定义的聚集(可能带有一个模式名限定),并且 expression 是任意自身不包含聚集表达式的值表达式或一个窗口函数调用。可选的 order_by_clause 和 filter_clause 描述如下。
第一种形式的聚集表达式为每一个输入行调用一次聚集。第二种形式和第一种相同,因为 ALL 是默认选项。第三种形式为输入行中表达式的每一个可区分值(或者对于多个表达式是值的可区分集合)调用一次聚集。第四种形式为每一个输入行调用一次聚集,因为没有特定的输入值被指定,它通常只对于 count() 聚集函数有用。最后一种形式被用于 *有序集 聚集函数,其描述如下。
大部分聚集函数忽略空输入,这样其中一个或多个表达式得到空值的行将被丢弃。除非另有说明,对于所有内建聚集都是这样。
例如,count(*) 得到输入行的总数。 count(f1) 得到输入行中 f1 为非空的数量,因为 count 忽略空值。而 count(distinct f1) 得到 f1 的非空可区分值的数量。
一般地,交给聚集函数的输入行是未排序的。在很多情况中这没有关系,例如不管接收到什么样的输入, min 总是产生相同的结果。但是,某些聚集函数(例如 array_agg 和 string_agg )依据输入行的排序产生结果。当使用这类聚集时,可选的 order_by_clause 可以被用来指定想要的顺序。order_by_clause 与查询级别的 ORDER BY 子句(如 第 7.5 节 所述)具有相同的语法,除非它的表达式总是仅有表达式并且不能是输出列名称或编号。例如:
SELECT array_agg(a ORDER BY b DESC) FROM table;在处理多参数聚集函数时,注意 ORDER BY 出现在所有聚集参数之后。例如,要这样写:
SELECT string_agg(a, ',' ORDER BY a) FROM table;而不能这样写:
SELECT string_agg(a ORDER BY a, ',') FROM table; -- 不正确后者在语法上是合法的,但是它表示用两个`ORDER BY`键来调用一个单一参数聚集函数(第二个是无用的,因为它是一个常量)。
如果在 order_by_clause 之外指定了 DISTINCT ,那么所有的 ORDER BY 表达式必须匹配聚集的常规参数。也就是说,你不能在 DISTINCT 列表没有包括的表达式上排序。
有序集聚集的调用例子:
SELECT percentile_cont(0.5) WITHIN GROUP (ORDER BY income) FROM households;
percentile_cont
-----------------
50489这会从表 households 的 income 列得到第 50 个百分位或者中位的值。 这里`0.5`是一个直接参数,对于百分位部分是一个 在不同行之间变化的值的情况它没有意义。
如果指定了 FILTER ,那么只有对 filter_clause 计算为真的输入行会被交给该聚集函数,其他行会被丢弃。例如:
SELECT
count(*) AS unfiltered,
count(*) FILTER (WHERE i < 5) AS filtered
FROM generate_series(1,10) AS s(i);
unfiltered | filtered
------------+----------
10 | 4
(1 row)预定义的聚集函数在 第 9.21 节 中描述。其他聚集函数可以由用户增加。
一个聚集表达式只能出现在 SELECT 命令的结果列表或是 HAVING 子句中。在其他子句(如 WHERE )中禁止使用它,因为那些子句的计算在逻辑上是在聚集的结果被形成之前。
当一个聚集表达式出现在一个子查询中(见 第 4.2.11 节 和 第 9.23 节),聚集通常在该子查询的行上被计算。但是如果该聚集的参数(以及 filter_clause,如果有)只包含外层变量则会产生一个异常:该聚集则属于最近的那个外层,并且会在那个查询的行上被计算。该聚集表达式从整体上则是对其所出现于的子查询的一种外层引用,并且在那个子查询的任意一次计算中都作为一个常量。只出现在结果列表或 HAVING 子句的限制适用于该聚集所属的查询层次。
6.2.8. 窗口函数调用
一个*窗口函数调用*表示在一个查询选择的行的某个部分上应用一个聚集类的函数。和非窗口聚集函数调用不同,这不会被约束为将被选择的行分组为一个单一的输出行 — 在查询输出中每一个行仍保持独立。不过,窗口函数能够根据窗口函数调用的分组声明( PARTITION BY 列表)访问属于当前行所在分组中的所有行。一个窗口函数调用的语法是下列之一:
function_name ([expression [, expression ... ]]) [ FILTER ( WHERE filter_clause ) ] OVER window_name
function_name ([expression [, expression ... ]]) [ FILTER ( WHERE filter_clause ) ] OVER ( window_definition )
function_name ( * ) [ FILTER ( WHERE filter_clause ) ] OVER window_name
function_name ( * ) [ FILTER ( WHERE filter_clause ) ] OVER ( window_definition )其中 window_definition 的语法是
[ existing_window_name ]
[ PARTITION BY expression [, ...] ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ frame_clause ]可选的 frame_clause 是下列之一
{ RANGE | ROWS | GROUPS } frame_start [ frame_exclusion ]
{ RANGE | ROWS | GROUPS } BETWEEN frame_start AND frame_end [ frame_exclusion ]其中 frame_start 和 frame_end 可以是下面形式中的一种
UNBOUNDED PRECEDING
offset PRECEDING
CURRENT ROW
offset FOLLOWING
UNBOUNDED FOLLOWING而 frame_exclusion 可以是下列之一
EXCLUDE CURRENT ROW
EXCLUDE GROUP
EXCLUDE TIES
EXCLUDE NO OTHERS这里,expression 表示任何自身不含有窗口函数调用的值表达式。
window_name 是对定义在查询的 WINDOW 子句中的一个命名窗口声明的引用。还可以使用在 WINDOW 子句中定义命名窗口的相同语法在圆括号内给定一个完整的 window_definition,详见 SELECT 参考页。值得指出的是,OVER wname 并不严格地等价于 OVER (wname …),后者表示复制并修改窗口定义,并且在被引用窗口声明包括一个帧子句时会被拒绝。
PARTITION BY 选项将查询的行分组成为 分区,窗口函数会独立地处理它们。PARTITION BY 工作起来类似于一个查询级别的 GROUP BY 子句,不过它的表达式总是只是表达式并且不能是输出列的名称或编号。如果没有 PARTITION BY,该查询产生的所有行被当作一个单一分区来处理。ORDER BY 选项决定被窗口函数处理的一个分区中的行的顺序。它工作起来类似于一个查询级别的 ORDER BY 子句,但是同样不能使用输出列的名称或编号。如果没有 ORDER BY,行将被以未指定的顺序被处理。
frame_clause 指定构成 窗口帧 的行集合,它是当前分区的一个子集,窗口函数将作用在该帧而不是整个分区。帧中的行集合会随着哪一行是当前行而变化。在 RANGE、ROWS 或者 GROUPS 模式中可以指定帧,在每一种情况下,帧的范围都是从 frame_start 到 frame_end。如果 frame_end 被省略,则末尾默认为 CURRENT ROW。
UNBOUNDED PRECEDING 的一个 frame_start 表示该帧开始于分区的第一行,类似地 UNBOUNDED FOLLOWING 的一个 frame_end 表示该帧结束于分区的最后一行。
在 RANGE 或 GROUPS 模式中,CURRENT ROW 的一个 frame_start 表示帧开始于当前行的第一个 平级 行(被窗口的 ORDER BY 子句排序为与当前行等效的行),而 CURRENT ROW 的一个 frame_end 表示帧结束于当前行的最后一个平级行。在 ROWS 模式中,CURRENT ROW 就表示当前行。
在 offset PRECEDING 以及 offset FOLLOWING 帧选项中,offset 必须是一个不包含任何变量、聚集函数或者窗口函数的表达式。offset 的含义取决于帧模式:
-
在
ROWS模式中,offset必须得到一个非空、非负的整数,并且该选项表示帧开始于当前行之前或者之后指定数量的行。 -
在
GROUPS模式中,offset也必须得到一个非空、非负的整数,并且该选项表示帧开始于当前行的平级组之前或者之后指定数量的*平级组*,这里平级组是在ORDER BY顺序中等效的行集合(要使用GROUPS模式,在窗口定义中就必须有一个ORDER BY子句)。 -
在
RANGE模式中,这些选项要求ORDER BY子句正好指定一列。offset指定当前行中那一列的值与它在该帧中前面或后面的行中的列值的最大差值。offset表达式的数据类型会随着排序列的数据类型而变化。对于数字的排序列,它通常是与排序列相同的类型,但对于日期时间排序列它是一个interval。例如,如果排序列是类型date或者timestamp,我们可以写RANGE BETWEEN '1 day' PRECEDING AND '10 days' FOLLOWING。offset仍然要求是非空且非负,不过“非负”的含义取决于它的数据类型。
在任何一种情况下,到帧末尾的距离都受限于到分区末尾的距离,因此对于离分区末尾比较近的行来说,帧可能会包含比较少的行。
注意在 ROWS 以及 GROUPS 模式中, 0 PRECEDING 和 0 FOLLOWING 与 CURRENT ROW 等效。通常在 RANGE 模式中,这个结论也成立(只要有一种合适的、与数据类型相关的“零”的含义)。
frame_exclusion 选项允许当前行周围的行被排除在帧之外,即便根据帧的开始和结束选项应该把它们包括在帧中。EXCLUDE CURRENT ROW 会把当前行排除在帧之外。EXCLUDE GROUP 会把当前行以及它在顺序上的平级行都排除在帧之外。EXCLUDE TIES 把当前行的任何平级行都从帧中排除,但不排除当前行本身。EXCLUDE NO OTHERS 只是明确地指定不排除当前行或其平级行的这种默认行为。
默认的帧选项是 RANGE UNBOUNDED PRECEDING,它和 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 相同。如果使用 ORDER BY,这会把该帧设置为从分区开始一直到当前行的最后一个 ORDER BY 平级行的所有行。如果不使用 ORDER BY,就意味着分区中所有的行都被包括在窗口帧中,因为所有行都成为了当前行的平级行。
限制是 frame_start 不能是 UNBOUNDED FOLLOWING 、frame_end 不能是 UNBOUNDED PRECEDING,并且在上述 frame_start 和 frame_end 选项的列表中 frame_end 选择不能早于 frame_start 选择出现 — 例如不允许 RANGE BETWEEN CURRENT ROW AND offset PRECEDING,但允许 ROWS BETWEEN 7 PRECEDING AND 8 PRECEDING ,虽然它不会选择任何行。
如果指定了 FILTER ,那么只有对 filter_clause 计算为真的输入行会被交给该窗口函数,其他行会被丢弃。只有是聚集的窗口函数才接受 FILTER 。
内建的窗口函数在 表 9.60 中介绍。用户可以加入其他窗口函数。此外,任何内建的或者用户定义的通用聚集或者统计性聚集都可以被用作窗口函数(有序集和假想集聚集当前不能被用作窗口函数)。
使用 * 的语法被用来把参数较少的聚集函数当作窗口函数调用,例如 count(*) OVER (PARTITION BY x ORDER BY y)。星号(*)通常不被用于窗口相关的函数。窗口相关的函数不允许在函数参数列表中用 DISTINCT 或 ORDER BY。
只有在 SELECT 列表和查询的 ORDER BY 子句中才允许窗口函数调用。
6.2.9. 类型转换
一个类型造型指定从一种数据类型到另一种数据类型的转换。IvorySQL接受两种等价的类型造型语法:
CAST ( expression AS type )
expression::typeCAST 语法遵从 SQL,而用 :: 的语法是IvorySQL的历史用法。
当一个造型被应用到一种未知类型的值表达式上时,它表示一种运行时类型转换。只有已经定义了一种合适的类型转换操作时,该造型才会成功。注意这和常量的造型(如 第 4.1.2.7 节 中所示)使用不同。应用于一个未修饰串文字的造型表示一种类型到一个文字常量值的初始赋值,并且因此它将对任意类型都成功(如果该串文字的内容对于该数据类型的输入语法是可接受的)。
如果一个值表达式必须产生的类型没有歧义(例如当它被指派给一个表列),通常可以省略显式类型造型,在这种情况下系统会自动应用一个类型造型。但是,只有对在系统目录中被标记为“OK to apply implicitly”的造型才会执行自动造型。其他造型必须使用显式造型语法调用。这种限制是为了防止出人意料的转换被无声无息地应用。
还可以用像函数的语法来指定一次类型造型:
typename ( expression )不过,这只对那些名字也作为函数名可用的类型有效。例如,double precision 不能以这种方式使用,但是等效的 float8 可以。还有,如果名称 interval、time 和 timestamp 被用双引号引用,那么由于语法冲突的原因,它们只能以这种风格使用。因此,函数风格的造型语法的使用会导致不一致性并且应该尽可能被避免。
6.2.10. 排序规则表达式
COLLATE 子句会重载一个表达式的排序规则。它被追加到它适用的表达式:
expr COLLATE collation这里 collation 可能是一个受模式限定的标识符。COLLATE 子句比操作符绑得更紧,需要时可以使用圆括号。
如果没有显式指定排序规则,数据库系统会从表达式所涉及的列中得到一个排序规则,如果该表达式没有涉及列,则会默认采用数据库的默认排序规则。
COLLATE 子句的两种常见使用是重载 ORDER BY 子句中的排序顺序,例如:
SELECT a, b, c FROM tbl WHERE ... ORDER BY a COLLATE "C";以及重载具有区域敏感结果的函数或操作符调用的排序规则,例如:
SELECT * FROM tbl WHERE a > 'foo' COLLATE "C";注意在后一种情况中,COLLATE 子句被附加到我们希望影响的操作符的一个输入参数上。COLLATE 子句被附加到该操作符或函数调用的哪个参数上无关紧要,因为被操作符或函数应用的排序规则是考虑所有参数得来的,并且一个显式的 COLLATE 子句将重载所有其他参数的排序规则(不过,附加非匹配 COLLATE 子句到多于一个参数是一种错误。详见 第 24.2 节)。因此,这会给出和前一个例子相同的结果:
SELECT * FROM tbl WHERE a COLLATE "C" > 'foo';但是这是一个错误:
SELECT * FROM tbl WHERE (a > 'foo') COLLATE "C";因为它尝试把一个排序规则应用到 > 操作符的结果,而它的数据类型是非可排序数据类型 boolean。
6.2.11. 标量子查询
一个标量子查询是一种圆括号内的普通 SELECT 查询,它刚好返回一行一列(关于书写查询可见 第 7 章)。`SELECT`查询被执行并且该单一返回值被使用在周围的值表达式中。将一个返回超过一行或一列的查询作为一个标量子查询使用是一种错误(但是如果在一次特定执行期间该子查询没有返回行则不是错误,该标量结果被当做为空)。该子查询可以从周围的查询中引用变量,这些变量在该子查询的任何一次计算中都将作为常量。对于其他涉及子查询的表达式还可见 第 9.23 节。
例如,下列语句会寻找每个州中最大的城市人口:
SELECT name, (SELECT max(pop) FROM cities WHERE cities.state = states.name)
FROM states;6.2.12. 数组构造器
一个数组构造器是一个能构建一个数组值并且将值用于它的成员元素的表达式。一个简单的数组构造器由关键词 ARRAY、一个左方括号 [ 、一个用于数组元素值的表达式列表(用逗号分隔)以及最后的一个右方括号 ] 组成。例如:
SELECT ARRAY[1,2,3+4];
array
---------
{1,2,7}
(1 row)默认情况下,数组元素类型是成员表达式的公共类型,使用和 UNION 或 CASE 结构(见 第 10.5 节)相同的规则决定。你可以通过显式将数组构造器造型为想要的类型来重载,例如:
SELECT ARRAY[1,2,22.7]::integer[];
array
----------
{1,2,23}
(1 row)这和把每一个表达式单独地造型为数组元素类型的效果相同。关于造型的更多信息请见 第 4.2.9 节。
多维数组值可以通过嵌套数组构造器来构建。在内层的构造器中,关键词 ARRAY 可以被忽略。例如,这些语句产生相同的结果:
SELECT ARRAY[ARRAY[1,2], ARRAY[3,4]];
array
---------------
{{1,2},{3,4}}
(1 row)
SELECT ARRAY[[1,2],[3,4]];
array
---------------
{{1,2},{3,4}}
(1 row)因为多维数组必须是矩形的,处于同一层次的内层构造器必须产生相同维度的子数组。任何被应用于外层 ARRAY 构造器的造型会自动传播到所有的内层构造器。
多维数组构造器元素可以是任何得到一个正确种类数组的任何东西,而不仅仅是一个子- ARRAY 结构。例如:
CREATE TABLE arr(f1 int[], f2 int[]);
INSERT INTO arr VALUES (ARRAY[[1,2],[3,4]], ARRAY[[5,6],[7,8]]);
SELECT ARRAY[f1, f2, '{{9,10},{11,12}}'::int[]] FROM arr;
array
------------------------------------------------
{{{1,2},{3,4}},{{5,6},{7,8}},{{9,10},{11,12}}}
(1 row)你可以构造一个空数组,但是因为无法得到一个无类型的数组,你必须显式地把你的空数组造型成想要的类型。例如:
SELECT ARRAY[]::integer[];
array
-------
{}
(1 row)也可以从一个子查询的结果构建一个数组。在这种形式中,数组构造器被写为关键词 ARRAY 后跟着一个加了圆括号(不是方括号)的子查询。例如:
SELECT ARRAY(SELECT oid FROM pg_proc WHERE proname LIKE 'bytea%');
array
------------------------------------------------------------------
{2011,1954,1948,1952,1951,1244,1950,2005,1949,1953,2006,31,2412}
(1 row)
SELECT ARRAY(SELECT ARRAY[i, i*2] FROM generate_series(1,5) AS a(i));
array
----------------------------------
{{1,2},{2,4},{3,6},{4,8},{5,10}}
(1 row)子查询必须返回一个单一列。如果子查询的输出列是非数组类型, 结果的一维数组将为该子查询结果中的每一行有一个元素, 并且有一个与子查询的输出列匹配的元素类型。如果子查询的输出列 是一种数组类型,结果将是同类型的一个数组,但是要高一个维度。 在这种情况下,该子查询的所有行必须产生同样维度的数组,否则结果 就不会是矩形形式。
用 ARRAY 构建的一个数组值的下标总是从一开始。更多关于数组的信息,请见 第 8.15 节。
6.2.13. 行构造器
一个行构造器是能够构建一个行值(也称作一个组合类型)并用值作为其成员域的表达式。一个行构造器由关键词 ROW、一个左圆括号、用于行的域值的零个或多个表达式(用逗号分隔)以及最后的一个右圆括号组成。例如:
SELECT ROW(1,2.5,'this is a test');当在列表中有超过一个表达式时,关键词 ROW 是可选的。
一个行构造器可以包括语法 rowvalue .*,它将被扩展为该行值的元素的一个列表,就像在一个顶层 SELECT 列表(见 第 8.16.5 节)中使用 .* 时发生的事情一样。例如,如果表 t 有列 f1 和 f2,那么这些是相同的:
SELECT ROW(t.*, 42) FROM t;
SELECT ROW(t.f1, t.f2, 42) FROM t;默认情况下,由一个 ROW 表达式创建的值是一种匿名记录类型。如果必要,它可以被造型为一种命名的组合类型 — 或者是一个表的行类型,或者是一种用 CREATE TYPE AS 创建的组合类型。为了避免歧义,可能需要一个显式造型。例如:
CREATE TABLE mytable(f1 int, f2 float, f3 text);
CREATE FUNCTION getf1(mytable) RETURNS int AS 'SELECT $1.f1' LANGUAGE SQL;
-- 不需要造型因为只有一个 getf1() 存在
SELECT getf1(ROW(1,2.5,'this is a test'));
getf1
-------
1
(1 row)
CREATE TYPE myrowtype AS (f1 int, f2 text, f3 numeric);
CREATE FUNCTION getf1(myrowtype) RETURNS int AS 'SELECT $1.f1' LANGUAGE SQL;
-- 现在我们需要一个造型来指示要调用哪个函数:
SELECT getf1(ROW(1,2.5,'this is a test'));
ERROR: function getf1(record) is not unique
SELECT getf1(ROW(1,2.5,'this is a test')::mytable);
getf1
-------
1
(1 row)
SELECT getf1(CAST(ROW(11,'this is a test',2.5) AS myrowtype));
getf1
-------
11
(1 row)行构造器可以被用来构建存储在一个组合类型表列中的组合值,或者被传递给一个接受组合参数的函数。还有,可以比较两个行值,或者用 IS NULL 或 IS NOT NULL 测试一个行,例如:
SELECT ROW(1,2.5,'this is a test') = ROW(1, 3, 'not the same');
SELECT ROW(table.*) IS NULL FROM table; -- detect all-null rows6.2.14. 表达式计算规则
子表达式的计算顺序没有被定义。特别地,一个操作符或函数的输入不必按照从左至右或其他任何固定顺序进行计算。
此外,如果一个表达式的结果可以通过只计算其一部分来决定,那么其他子表达式可能完全不需要被计算。例如,如果我们写:
SELECT true OR somefunc();那么 somefunc() 将(可能)完全不被调用。如果我们写成下面这样也是一样:
SELECT somefunc() OR true;注意这和一些编程语言中布尔操作符从左至右的“短路”不同。
因此,在复杂表达式中使用带有副作用的函数是不明智的。在 WHERE 和 HAVING 子句中依赖副作用或计算顺序尤其危险,因为在建立一个执行计划时这些子句会被广泛地重新处理。这些子句中布尔表达式( AND / OR / NOT 的组合)可能会以布尔代数定律所允许的任何方式被重组。
当有必要强制计算顺序时,可以使用一个 CASE 结构(见 第 9.18 节)。例如,在一个 WHERE 子句中使用下面的方法尝试避免除零是不可靠的:
SELECT ... WHERE x > 0 AND y/x > 1.5;但是这是安全的:
SELECT ... WHERE CASE WHEN x > 0 THEN y/x > 1.5 ELSE false END;一个以这种风格使用的 CASE 结构将使得优化尝试失败,因此只有必要时才这样做(在这个特别的例子中,最好通过写 y > 1.5*x 来回避这个问题)。
不过,CASE 不是这类问题的万灵药。上述技术的一个限制是, 它无法阻止常量子表达式的提早计算。如 第 38.7 节 中所述,当查询被规划而不是被执行时,被标记成 IMMUTABLE 的函数和操作符可以被计算。因此
SELECT CASE WHEN x > 0 THEN x ELSE 1/0 END FROM tab;很可能会导致一次除零失败,因为规划器尝试简化常量子表达式。即便是 表中的每一行都有 x > 0(这样运行时永远不会进入到 ELSE 分支)也是这样。
虽然这个特别的例子可能看起来愚蠢,没有明显涉及常量的情况可能会发生 在函数内执行的查询中,因为因为函数参数的值和本地变量可以作为常量 被插入到查询中用于规划目的。例如,在PL/pgSQL函数 中,使用一个 IF -THEN -ELSE 语句来 保护一种有风险的计算比把它嵌在一个 CASE 表达式中要安全得多。
另一个同类型的限制是,一个 CASE 无法阻止其所包含的聚集表达式 的计算,因为在考虑 SELECT 列表或 HAVING 子句中的 其他表达式之前,会先计算聚集表达式。例如,下面的查询会导致一个除零错误, 虽然看起来好像已经这种情况加以了保护:
SELECT CASE WHEN min(employees) > 0
THEN avg(expenses / employees)
END
FROM departments;min() 和 avg() 聚集会在所有输入行上并行地计算, 因此如果任何行有 employees 等于零,在有机会测试 min() 的结果之前,就会发生除零错误。取而代之的是,可以使用 一个 WHERE 或 FILTER 子句来首先阻止有问题的输入行到达一个聚集函数。
6.3. 调用函数
IvorySQL允许带有命名参数的函数被使用 位置 或 命名 记号法调用。命名记号法对于有大量参数的函数特别有用,因为它让参数和实际参数之间的关联更明显和可靠。在位置记号法中,书写一个函数调用时,其参数值要按照它们在函数声明中被定义的顺序书写。在命名记号法中,参数根据名称匹配函数参数,并且可以以任何顺序书写。对于每一种记法,还要考虑函数参数类型的效果,这些在 第 10.3 节 有介绍。
在任意一种记号法中,在函数声明中给出了默认值的参数根本不需要在调用中写出。但是这在命名记号法中特别有用,因为任何参数的组合都可以被忽略。而在位置记号法中参数只能从右往左忽略。
IvorySQL也支持 混合 记号法,它组合了位置和命名记号法。在这种情况中,位置参数被首先写出并且命名参数出现在其后。
下列例子将展示所有三种记号法的用法:
CREATE FUNCTION concat_lower_or_upper(a text, b text, uppercase boolean DEFAULT false)
RETURNS text
AS
$$
SELECT CASE
WHEN $3 THEN UPPER($1 || ' ' || $2)
ELSE LOWER($1 || ' ' || $2)
END;
$$
LANGUAGE SQL IMMUTABLE STRICT;函数 concat_lower_or_upper 有两个强制参数,a 和 b。此外,有一个可选的参数 uppercase,其默认值为 false。a 和 b 输入将被串接,并且根据 uppercase 参数被强制为大写或小写形式。这个函数的剩余细节对这里并不重要(详见 第 38 章)。
6.3.1. 使用位置记号
在IvorySQL中,位置记号法是给函数传递参数的传统机制。一个例子:
SELECT concat_lower_or_upper('Hello', 'World', true);
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)所有参数被按照顺序指定。结果是大写形式,因为 uppercase 被指定为 true。另一个例子:
SELECT concat_lower_or_upper('Hello', 'World');
concat_lower_or_upper
-----------------------
hello world
(1 row)这里,uppercase 参数被忽略,因此它接收它的默认值 false,并导致小写形式的输出。在位置记号法中,参数可以按照从右往左被忽略并且因此而得到默认值。
6.3.2. 使用命名记号
在命名记号法中,每一个参数名都用 ⇒ 指定来把它与参数表达式分隔开。例如:
SELECT concat_lower_or_upper(a => 'Hello', b => 'World');
concat_lower_or_upper
-----------------------
hello world
(1 row)再次,参数 uppercase 被忽略,因此它被隐式地设置为 false。使用命名记号法的一个优点是参数可以用任何顺序指定,例如:
SELECT concat_lower_or_upper(a => 'Hello', b => 'World', uppercase => true);
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)
SELECT concat_lower_or_upper(a => 'Hello', uppercase => true, b => 'World');
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)为了向后兼容性,基于 ":=" 的旧语法仍被支持:
SELECT concat_lower_or_upper(a := 'Hello', uppercase := true, b := 'World');
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)6.3.3. 使用混合记号
混合记号法组合了位置和命名记号法。不过,正如已经提到过的,命名参数不能超越位置参数。例如:
SELECT concat_lower_or_upper('Hello', 'World', uppercase => true);
concat_lower_or_upper
-----------------------
HELLO WORLD
(1 row)在上述查询中,参数 a 和 b 被以位置指定,而 uppercase 通过名字指定。在这个例子中,这只增加了一点文档。在一个具有大量带默认值参数的复杂函数中,命名的或混合的记号法可以节省大量的书写并且减少出错的机会。
7. Oracle兼容功能
7.1. 配置参数
参数设置采用与原生 PostgreSQL 相同的方法。 所有参数名称都不区分大小写。每个参数都采用以下五种类型之一的值:布尔值、字符串、整数、浮点数或枚举 (enum)。
7.1.1. compatible_mode (enum)
此参数控制数据库服务器的行为。 默认值为 postgres,表示它是原生安装,服务器将作为原生 PG 安装。 如果它设置为“oracle”,那么查询的输出和系统行为整体会发生变化,因为它会更像 Oracle。
当设置为 oracle 时,此参数会隐式地将同样名字的Schema添加到 search_path。 以便可以定位 Oracle 兼容对象。
该参数可以通过 postgresql.conf 配置文件设置,对整个数据库生效。 或者可以通过客户端使用 set 命令在会话上进行设置。
7.2. 包
本节将介绍PostgreSQL的“Oracle风格包”。根据定义,包是一个对象或一组对象打包在一起。就数据库而言,这将转换为一个命名的模式对象,该对象将过程、函数、变量、游标、用户定义的记录类型和引用记录的逻辑分组集合打包在自己内部。希望用户熟悉PostgreSQL,并且对SQL语言有很好的理解,以便更好地理解这些包并更有效地使用它们。
7.2.1. 对软件包的需求
与其他各种编程语言中的类似构造一样,将包与SQL一起使用有很多好处。在本节中,我们将要讲几个。
- 1.代码包的可靠性和可复用性
-
Packages使您能够创建封装代码的模块化对象。这使得总体设计和实现更加简单。通过封装变量和相关类型、存储过程/函数以及游标,它允许您创建一个简单、易于理解、易于维护和使用的独立的模块。封装通过公开包接口而不是包体的实现细节发挥作用。因此,这在许多方面都有好处。它允许应用程序和用户引用一致的界面,而不必担心其主体的内容。此外,它还防止用户根据代码实现做出任何决策,因为代码实现从来没有向他们公开过。
- 2.易用性
-
在PostgreSQL中创建一致的功能接口的能力有助于简化应用程序开发,因为它允许在没有主体的情况下编译包。在开发阶段之后,包允许用户管理整个包的访问控制,而不是单个对象。这非常有价值,尤其是当包包含许多模式对象时。
- 3.性能
-
包是加载到内存中进行维护,因此使用的I/O资源最少。重新编译很简单,仅限于更改的对象;不重新编译从属对象。
- 4.附加功能
-
除了性能和易用性之外,软件包还为变量和游标提供了会话范围的持久性。这意味着变量和游标与数据库会话具有相同的生存期,并在会话被销毁时被销毁。
7.2.2. 包组件
包有一个接口和一个主体,这是组成包的主要组件。
1.包规格
包规格指定了包内从外部使用的任何对象。这指的是可公开访问的接口。它不包含它们的定义或实现,即功能和程序。它只定义了标题,而没有正文定义。可以初始化变量。以下是可在规范中列出的对象列表:
-
Functions
-
Procedures
-
Cursors
-
Types
-
Variables
-
Constants
-
Record types
2.包体
包体包含包的所有实现代码,包括公共接口和私有对象。如果规范不包含任何子程序或游标,则包体是可选的。
它必须包含规范中声明的子程序的定义,并且相应的定义必须匹配。
包体可以包含其自己的子程序和规范中未指定的任何内部对象的类型声明。这些对象被认为是私有的。无法在包外部访问私有对象。
除了子程序定义外,它还可以选择性地包含一个初始化程序块,用于初始化规范中声明的变量,并且在会话中首次调用包时仅执行一次。
7.2.3. 包语法
7.2.3.1. 包规范语法
CREATE [ OR REPLACE ] PACKAGE [schema.] *package_name* [invoker_rights_clause] [IS | AS]
item_list[, item_list ...]
END [*package_name*];
invoker_rights_clause:
AUTHID [CURRENT_USER | DEFINER]
item_list:
[
function_declaration |
procedure_declaration |
type_definition |
cursor_declaration |
item_declaration
]
function_declaration:
FUNCTION function_name [(parameter_declaration[, ...])] RETURN datatype;
procedure_declaration:
PROCEDURE procedure_name [(parameter_declaration[, ...])]
type_definition:
record_type_definition |
ref_cursor_type_definition
cursor_declaration:
CURSOR name [(cur_param_decl[, ...])] RETURN rowtype;
item_declaration:
cursor_declaration |
cursor_variable_declaration |
record_variable_declaration |
variable_declaration |
record_type_definition:
TYPE record_type IS RECORD ( variable_declaration [, variable_declaration]... ) ;
ref_cursor_type_definition:
TYPE type IS REF CURSOR [ RETURN type%ROWTYPE ];
cursor_variable_declaration:
curvar curtype;
record_variable_declaration:
recvar { record_type | rowtype_attribute | record_type%TYPE };
variable_declaration:
varname datatype [ [ NOT NULL ] := expr ]
parameter_declaration:
parameter_name [IN] datatype [[:= | DEFAULT] expr]7.2.3.2. 包体语法
CREATE [ OR REPLACE ] PACKAGE BODY [schema.] package_name [IS | AS]
[item_list[, item_list ...]] |
item_list_2 [, item_list_2 ...]
[initialize_section]
END [package_name];
initialize_section:
BEGIN statement[, ...]
item_list:
[
function_declaration |
procedure_declaration |
type_definition |
cursor_declaration |
item_declaration
]
item_list_2:
[
function_declaration
function_definition
procedure_declaration
procedure_definition
cursor_definition
]
function_definition:
FUNCTION function_name [(parameter_declaration[, ...])] RETURN datatype [IS | AS]
[declare_section] body;
procedure_definition:
PROCEDURE procedure_name [(parameter_declaration[, ...])] [IS | AS]
[declare_section] body;
cursor_definition:
CURSOR name [(cur_param_decl[, ...])] RETURN rowtype IS select_statement;
body:
BEGIN statement[, ...] END [name];
statement:
[<<LABEL>>] pl_statments[, ...];7.2.3.3. 描述
创建包定义一个新包。创建或替换包将创建新包或替换现有定义。
如果包含架构名称,则在指定架构中创建包。否则,它将在当前架构中创建。新包的名称在架构中必须是唯一的。
使用“创建或替换包”替换现有包时,包的所有权和权限不会更改。所有其他包属性都被指定为命令中指定或隐含的值。您必须拥有该包才能替换它(这包括作为所属角色的成员)。
创建包的用户成为包的所有者。
7.2.3.4. 参数
package_name 要创建的包的名称(可选架构限定)。
invoker_rights_clause 调用方权限定义包对数据库对象的访问权限。可供选择的选项有:
-
CURRENT_USER 将使用执行包的当前用户的访问权限。
-
DEFINER 将使用包创建者的访问权限。
item_list 这是可以作为包的一部分的项目列表。
procedure_declaration 指定过程名称及其参数列表。这只是一个声明,不会定义过程。
当此声明是包规范的一部分时,它是一个公共过程,必须将其定义添加到包体中。
当它是包体的一部分时,它充当转发声明,是一个只有包元素才能访问的私有过程。
procedure_definition 程序在包体中定义。这定义了先前声明的过程。它还可以定义一个过程,而不需要任何先前的声明,这将使它成为一个私有过程。
function_declaration 定义函数名、参数及其返回类型。它只是一个声明,不会定义函数。
当此声明是包规范的一部分时,它是一个公共函数,必须将其定义添加到包体中。
当它是包体的一部分时,它充当转发声明,是一个只有包元素才能访问的私有函数。
function_definition 这些函数在包体中定义。这定义了前面声明的函数。它还可以定义一个函数,而不需要任何先前的声明,这将使它成为一个私有函数。
type_definition 建议您可以定义记录或光标类型。
cursor_declaration 定义游标声明必须包括其参数和返回类型作为所需的行类型。
item_declaration 允许声明:
-
Cursors
-
Cursor variables
-
Record variables
-
Variables
parameter_declaration 定义用于声明参数的语法。如果指定了关键字“IN”,则表示这是一个输入参数。后跟表达式(或值)的默认关键字只能特定于输入参数。
declare_section 它包含函数或过程本地的所有元素,并且可以在其主体中引用。
body 主体由PL/iSQL语言支持的SQL语句或PL控制结构组成。
7.2.4. 创建和访问包
7.2.4.2. 访问包元素
当包第一次在会话中被引用时,它将被实例化和初始化。以下操作在过程中执行这个过程:
-
将初始值分配给公共常量和变量
-
执行包的初始值设定项块
有几种方法可以访问包元素:
-
包函数可以像SELECT语句或其他PL块中的任何其他函数一样使用
-
包过程可以使用CALL直接调用,也可以从其他PL块调用
-
包变量可以使用PL块中的包名称限定或从SQL提示符直接读取和写入。
-
使用点符号直接访问: 在点表示法中,可以通过以下方式访问元素:
-
package_name.func('foo');
-
package_name.proc('foo');
-
package_name.variable;
-
package_name.constant;
-
package_name.other_package.func('foo');
这些语句可以从PL块内部使用,如果元素不是类型声明或过程,则可以在SELECT语句中使用。
-
-
SQL调用语句: 另一种方法是使用CALL语句。CALL语句执行独立过程,或在类型或包中定义的函数。
-
CALL package_name.func('foo');
-
CALL package_name.proc('foo');
-
7.2.5. 了解可见性的范围
PL/SQL块中声明的变量范围仅限于该块。如果它有嵌套块,则它将是嵌套块的全局变量。
类似地,如果两个块都声明了相同的名称变量,那么在嵌套块内部,它自己声明的变量是可见的,父变量是不可见的。要访问父变量,该变量必须完全限定。
考虑下面的代码片段。
7.2.6. 示例:可见性和限定变量名
<<blk_1>>
DECLARE
x INT;
y INT;
BEGIN
-- both blk_1.x and blk_1.y are visible
<<blk_2>>
DECLARE
x INT;
z INT;
BEGIN
-- blk_2.x, y and z are visible
-- to access blk_1.x it has to be a qualified name. blk_1.x := 0; NULL;
END;
-- both x and y are visible
END;上面的示例显示了当嵌套包包含同名变量时,必须如何完全限定变量名。
变量名限定有助于解决在以下情况下由作用域优先级引入的可能混淆:
-
包和嵌套包变量:如果没有限定,嵌套的优先
-
包变量和列名:如果没有限定,列名优先
-
功能或程序变量和包变量:如果没有限定,包变量优先。
以下类型中的字段或方法需要进行类型限定。
-
记录类型
示例:记录类型可见性和访问权限
DECLARE
x INT;
TYPE xRec IS RECORD (x char, y INT);
BEGIN
x := 1; -- will always refer to x(INT) type.
xRec.x := '2'; -- to refer the CHAR type, it will have to be
qualified name
END;7.2.7. 包示例
7.2.7.1. 包规格
CREATE TABLE test(x INT, y VARCHAR2(100));
INSERT INTO test VALUES (1, 'One');
INSERT INTO test VALUES (2, 'Two');
INSERT INTO test VALUES (3, 'Three');
-- Package specification:
CREATE OR REPLACE PACKAGE example AUTHID DEFINER AS
-- Declare public type, cursor, and exception:
TYPE rectype IS RECORD (a INT, b VARCHAR2(100));
CURSOR curtype RETURN rectype%rowtype;
rec rectype;
-- Declare public subprograms:
FUNCTION somefunc (
last_name VARCHAR2,
first_name VARCHAR2,
email VARCHAR2
) RETURN NUMBER;
-- Overload preceding public subprogram:
PROCEDURE xfunc (emp_id NUMBER);
PROCEDURE xfunc (emp_email VARCHAR2);
END example;
/7.2.7.2. 包体
-- Package body:
CREATE OR REPLACE PACKAGE BODY example AS
nelems NUMBER; -- private variable, visible only in this package
-- Define cursor declared in package specification:
CURSOR curtype RETURN rectype%rowtype IS SELECT x, y
FROM test
ORDER BY x;
-- Define subprograms declared in package specification:
FUNCTION somefunc (
last_name VARCHAR2,
first_name VARCHAR2,
email VARCHAR2
) RETURN NUMBER IS
id NUMBER := 0;
BEGIN
OPEN curtype;
LOOP
FETCH curtype INTO rec;
EXIT WHEN NOT FOUND;
END LOOP;
RETURN rec.a;
END;
PROCEDURE xfunc (emp_id NUMBER) IS
BEGIN
NULL;
END;
PROCEDURE xfunc (emp_email VARCHAR2) IS
BEGIN
NULL;
END;
BEGIN -- initialization part of package body
nelems := 0;
END example;
/
SELECT example.somefunc('Joe', 'M.', 'email@example.com');7.3. 更改表
7.3.1. 语法
ALTER TABLE [ IF EXISTS ] [ ONLY ] name [ * ]
action;
action:
ADD ( add_coldef [, ... ] )
| MODIFY ( modify_coldef [, ... ] )
| DROP [ COLUMN ] ( column_name [, ... ] )
add_coldef:
cloumn_name data_type
modify_coldef:
cloumn_name data_type alter_using
alter_using:
USING expression7.3.2. 参数
name 表名.
cloumn_name 列名.
data_type 列类型.
expression 值表达式.
ADD keyword 增加表的列, 可以增加一个列或多个列.
MODIFY keyword 修改表的列, 可以修改一个列或多个列.
DROP keyword 删除表的列, 可以删除一个列或多个列.
USING keyword 修改列的值.
7.3.3. 示例
ADD:
create table tb_test1(id int, flg char(10));
alter table tb_test1 add (name varchar);
alter table tb_test1 add (adress varchar, num int, flg1 char);
\d tb_test1
Table "public.tb_test1"
Column | Type | Collation | Nullable | Default
--------+-------------------+-----------+----------+---------
id | integer | | |
flg | character(10) | | |
name | character varying | | |
adress | character varying | | |
num | integer | | |
flg1 | character(1) | | |
MODIFY:
create table tb_test2(id int, flg char(10), num varchar);
insert into tb_test2 values('1', 2, '3');
alter table tb_test2 modify(id char);
\d tb_test2
Table "public.tb_test2"
Column | Type | Collation | Nullable | Default
--------+-------------------+-----------+----------+---------
id | character(1) | | |
flg | character(10) | | |
num | character varying | | |
DROP:
create table tb_test3(id int, flg1 char(10), flg2 char(11), flg3 char(12), flg4 char(13),
flg5 char(14), flg6 char(15));
alter table tb_test3 drop column(id);
\d tb_test3
Table "public.tb_test3"
Column | Type | Collation | Nullable | Default
--------+---------------+-----------+----------+---------
flg1 | character(10) | | |
flg2 | character(11) | | |
flg3 | character(12) | | |
flg4 | character(13) | | |
flg5 | character(14) | | |
flg6 | character(15) | | |7.4. 删除表
7.4.1. 语法
[ WITH [ RECURSIVE ] with_query [, ...] ]
DELETE [ FROM ] [ ONLY ] table_name [ * ] [ [ AS ] alias ]
[ USING using_list ]
[ WHERE condition | WHERE CURRENT OF cursor_name ]
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]7.5. 更新表
7.5.1. 语法
[ WITH [ RECURSIVE ] with_query [, ...] ]
UPDATE [ ONLY ] table_name [ * ] [ [ AS ] alias ]
SET { [ table_name | alias ] column_name = { expression | DEFAULT }
| ( [ table_name | alias ] column_name [, ...] ) = [ ROW ] ( { expression | DEFAULT } [, ...] )
| ( [ table_name | alias ] column_name [, ...] ) = ( sub-SELECT )
} [, ...]
[ FROM from_list ]
[ WHERE condition | WHERE CURRENT OF cursor_name ]
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]7.6. GROUP BY
7.6.1. 示例
set compatible_mode to oracle;
create table students(student_id varchar(20) primary key ,
student_name varchar(40),
student_pid int);
select student_id,student_name from students group by student_id;
ERROR: column "students.student_name" must appear in the GROUP BY clause or be used in an aggregate function7.8. Minus Operator
7.9. 转移字符
7.11. 兼容时间和日期函数
7.11.1. from_tz
7.11.1.3. 例子
select oracle.from_tz('2021-11-08 09:12:39','Asia/Shanghai') from dual;
from_tz
-----------------------------------
2021-11-08 09:12:39 Asia/Shanghai
(1 row)
select oracle.from_tz('2021-11-08 09:12:39','SAST') from dual;
from_tz
--------------------------
2021-11-08 09:12:39 SAST
select oracle.from_tz(NULL,'SAST') from dual;
from_tz
---------
(1 row)
select oracle.from_tz('2021-11-08 09:12:31',NULL) from dual;
from_tz
---------
(1 row)7.11.2. numtodsinterval
7.11.2.3. 例子
select oracle.numtodsinterval(2147483646.1232131232,'day') from dual;
numtodsinterval
--------------------------------------------------
@ 2147483646 days 2 hours 57 mins 25.607758 secs
(1 row)
select oracle.numtodsinterval(2147483647.1232131232,'hour') from dual;
numtodsinterval
------------------------------------------
@ 2147483647 hours 7 mins 23.567104 secs
(1 row)
select oracle.numtodsinterval(7730941132799.1232131232,'second') from dual;
numtodsinterval
-------------------------------------------
@ 2147483647 hours 59 mins 59.123456 secs
(1 row)
select oracle.numtodsinterval(NULL,'second') from dual;
numtodsinterval
-----------------
(1 row)
select oracle.numtodsinterval(7730941132800.1232131232,NULL) from dual;
numtodsinterval
-----------------
(1 row)7.11.3. numtoyminterval
7.11.3.3. 例子
select oracle.numtoyminterval(178956970.1232131232,'year') from dual;
numtoyminterval
-------------------------------------------------------------
@ 178956970 years 1 mon 14 days 8 hours 33 mins 40.608 secs
(1 row)
select oracle.numtoyminterval(2147483646.1232131232,'month') from dual;
numtoyminterval
---------------------------------------------------------------
@ 178956970 years 6 mons 3 days 16 hours 42 mins 48.2688 secs
(1 row)
select oracle.numtoyminterval(NULL,'month') from dual;
numtoyminterval
-----------------
(1 row)
select oracle.numtoyminterval(2147483647.1232131232,NULL) from dual;
numtoyminterval
-----------------
(1 row)7.11.8. days_between
7.11.8.3. 例子
select oracle.days_between('2021-11-25 15:33:16'::timestamp,'2019-01-01 00:00:00'::timestamp) from dual;
days_between
------------------
1059.64810185185
(1 row)
select oracle.days_between('2019-09-08 09:09:09'::timestamp,'2019-01-01 00:00:00'::timestamp) from dual;
days_between
------------------
250.381354166667
(1 row)
select oracle.days_between('2021-11-25 09:09:09'::oracle.date,'2019-01-01 00:00:00'::oracle.date) from dual;
days_between
------------------
1059.38135416667
(1 row)
select oracle.days_between(NULL,NULL) from dual;
days_between
--------------
(1 row)7.11.9. days_between_tmtz
7.11.9.3. 例子
select oracle.days_between_tmtz('2019-09-08 09:09:09+08'::timestamptz,'2019-05-08 12:34:09+08'::timestamptz) from dual;
days_between_tmtz
-------------------
122.857638888889
(1 row)
select oracle.days_between_tmtz('2019-09-08 09:09:09+08'::timestamptz,'2019-05-08 12:34:09+09'::timestamptz) from dual;
days_between_tmtz
-------------------
122.899305555556
(1 row)
select oracle.days_between_tmtz(NULL,NULL) from dual;
days_between_tmtz
-------------------
(1 row)7.11.10. add_days_to_timestamp
7.11.10.3. 例子
select oracle.add_days_to_timestamp('1009-09-15 09:00:00'::timestamp, '3267.123'::numeric) from dual;
add_days_to_timestamp
-----------------------
1018-08-26 11:57:07.2
(1 row)
select oracle.add_days_to_timestamp(NULL, '3267.123'::numeric) from dual;
add_days_to_timestamp
-----------------------
(1 row)7.11.11. subtract
7.11.11.3. 例子
select oracle.subtract('2019-11-25 16:51:20'::timestamptz,'3267.123'::numeric) from dual;
subtract
--------------------------
2010-12-15 13:54:12.8+08
(1 row)
select oracle.subtract('2019-11-25 16:51:20'::timestamptz, '2018-11-25 16:51:12'::timestamp) from dual;
subtract
------------
365.000093
(1 row)
select oracle.subtract('2019-11-25 16:51:20'::oracle.date,'3267.123'::numeric) from dual;
subtract
-----------------------
2010-12-15 13:54:12.8
(1 row)
select oracle.subtract('2019-11-25 16:51:20'::oracle.date,'2017-02-21 13:51:20'::oracle.date) from dual;
subtract
----------
1007.125
(1 row)7.11.12. next_day
7.11.12.1. 目的
next_day 返回由格式名相同的第一个工作日的日期,该日期晚于当前日期。 无论日期的数据类型如何,返回类型始终为 DATE。 返回值具有与参数日期相同的小时、分钟和秒部分。7.11.12.2. 参数描述
参数 |
描述 |
value |
开始时间戳 |
weekday |
星期几,可以是 "Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday" 或者 0,1,2,3,4,5,6,0代表星期天 |
7.11.12.3. 例子
select oracle.next_day(to_timestamp('2020-02-29 14:40:50', 'YYYY-MM-DD HH24:MI:SS'), 'Tuesday') from dual;
next_day
---------------------
2020-03-03 14:40:50
(1 row)
select oracle.next_day('2020-07-01 19:43:51 +8'::timestamptz, 1) from dual;
next_day
---------------------
2020-07-05 19:43:51
(1 row)
select oracle.next_day(oracle.date '2020-09-15 12:13:29', 6) from dual;
next_day
---------------------
2020-09-18 12:13:29
(1 row)7.11.13. last_day
7.11.13.3. 例子
select oracle.last_day(timestamp '2020-05-17 13:27:19') from dual;
last_day
---------------------
2020-05-31 13:27:19
(1 row)
select oracle.last_day('2020-11-29 19:20:40 +08'::timestamptz) from dual;
last_day
---------------------
2020-11-30 19:20:40
(1 row)
select oracle.last_day('-0004-2-1 13:27:19'::oracle.date) from dual;
last_day
----------------------
-0004-02-29 13:27:19
(1 row)7.11.14. add_months
7.11.14.3. 例子
select oracle.add_months(oracle.date '2020-02-15',7) from dual;
add_months
---------------------
2020-09-15 00:00:00
(1 row)
select oracle.add_months(timestamp '2018-12-15 19:12:09',12) from dual;
add_months
---------------------
2019-12-15 19:12:09
(1 row)
select oracle.add_months(timestamptz'2018-12-15 12:12:09 +08',120) from dual;
add_months
---------------------
2028-12-15 12:12:09
(1 row)7.11.15. months_between
7.11.15.3. 例子
select oracle.months_between(oracle.date '2021-11-10 12:11:10', oracle.date '2020-05-20 19:40:21') from dual;
months_between
------------------
17.6673570041816
(1 row)
select oracle.months_between(timestamp '2022-05-15 20:20:20', timestamp '2020-01-20 19:20:20') from dual;
months_between
------------------
27.8400537634409
(1 row)
select oracle.months_between(timestamptz '2020-01-10 01:00:00 +08', timestamptz '2028-05-19 16:25:20 +08') from dual;
months_between
-------------------
-100.311051373955
(1 row)7.11.17. new_time
7.11.17.1. 目的
转换第一个时区的时间到第二个时区的时间. 时区包括了 "ast", "adt", "bst", "bdt", "cst", "cdt", "est", "edt", "gmt", "hst", "hdt", "mst", "mdt", "nst", "pst", "pdt", "yst", "ydt".7.11.17.3. 例子
select oracle.new_time(timestamp '2020-12-12 17:45:18', 'AST', 'ADT') from dual;
new_time
---------------------
2020-12-12 18:45:18
(1 row)
select oracle.new_time(timestamp '2020-12-12 17:45:18', 'BST', 'BDT') from dual;
new_time
---------------------
2020-12-12 18:45:18
(1 row)
select oracle.new_time(timestamp '2020-12-12 17:45:18', 'CST', 'CDT') from dual;
new_time
---------------------
2020-12-12 18:45:18
(1 row)7.11.18. trunc
7.11.18.1. 目的
trunc函数返回一个日期, 按照指定格式被截断, fmt包括 "Y", "YY", "YYY", "YYYY","YEAR", "SYYYY", "SYEAR", "I", "IY", "IYY", "IYYY", "Q", "WW", "Iw", "W", "DAY", "DY", "D", "MONTH", "MONn", "MM", "RM", "CC", "SCC", "DDD", "DD", "J", "HH", "HH12", "HH24", "MI".7.11.18.3. 例子
select oracle.trunc(cast('2050-12-12 12:12:13' as oracle.date), 'SCC');
trunc
---------------------
2001-01-01 00:00:00
(1 row)
select oracle.trunc(timestamp '2020-07-28 19:16:12', 'Q');
trunc
---------------------
2020-07-01 00:00:00
(1 row)
select oracle.trunc(timestamptz '2020-09-27 18:30:21 + 08', 'MONTH');
trunc
------------------------
2020-09-01 00:00:00+08
(1 row)7.11.19. round
7.11.19.1. 目的
round函数返回一个日期,按照指定的格式四舍五入, fmt 包括了 "Y", "YY", "YYY", "YYYY","YEAR", "SYYYY", "SYEAR", "I", "IY", "IYY", "IYYY", "Q", "WW", "Iw", "W", "DAY", "DY", "D", "MONTH", "MONn", "MM", "RM", "CC", "SCC", "DDD", "DD", "J", "HH", "HH12", "HH24", "MI".7.11.19.3. 例子
select oracle.round(cast('2051-12-12 19:00:00' as oracle.date), 'SCC');
round
---------------------
2101-01-01 00:00:00
(1 row)
select oracle.round(timestamp '2050-06-12 16:40:55', 'IYYY');
round
---------------------
2050-01-03 00:00:00
(1 row)
select oracle.round(timestamptz '2020-02-16 19:16:12 + 08', 'Q');
round
------------------------
2020-04-01 00:00:00+08
(1 row)7.12. 兼容转换和比较以及与NULL相关的函数
7.12.1. TO_CHAR
7.12.2. TO_NUMBER
7.12.2.1. 目的
TO_NUMBER(str,[fmt1]) 根据给定的格式将输入参数 str 转换为 NUMREIC 数据类型的值。 如果省略 fmt1,则数据将转换为系统默认格式的 NUMERIC 值。 如果 str 是 NUMERIC,则该函数返回 str。如果 str 计算结果为 null,则该函数返回 null。 如果它不能转换为 NUMERIC 数据类型,则该函数返回错误。
7.12.4. TO_BINARY_DOUBLE
7.12.4.1. 目的
TO_BINARY_DOUBLE(str) 将输入参数 str 转换为双精度浮点数的值。 如果 str 的计算结果为 null,则该函数返回 null。 如果不能转换为双精度浮点数据类型或超出双精度浮点数的范围,则函数返回错误。
7.12.4.3. 示例
select to_binary_double('1.2');
to_binary_double
------------------
1.2
(1 row)
select to_binary_double('1.2'::text);
to_binary_double
------------------
1.2
(1 row)
select to_binary_double(1.2::numeric);
to_binary_double
------------------
1.2
(1 row)
select to_binary_double(123456789123456789.45566::numeric);
to_binary_double
------------------------
1.2345678912345678e+17
(1 row)
select to_binary_double(NULL);
to_binary_double
------------------
(1 row)7.12.5. TO_BINRAY_FLOAT
7.12.5.1. 目的
TO_BINARY_FLOAT(str) 将输入参数 str 转换为单精度浮点数。 如果str计算结果为null,则函数返回null。 如果无法转换为单精度浮点数据类型或超出单精度浮点数的范围,则函数返回错误。
7.12.5.3. 示例
select to_binary_float(2.5555::float8);
to_binary_float
-----------------
2.5555
(1 row)
select to_binary_float('123'::text);
to_binary_float
-----------------
123
(1 row)
select to_binary_float(1.2::numeric);
to_binary_float
-----------------
1.2
(1 row)
select to_binary_float(NULL);
to_binary_float
-----------------
(1 row)7.12.9. TO_DATE
7.12.9.1. 目的
TO_DATE(str,[fmt]) 根据给定的格式将输入参数 str 转换为日期数据类型的值。 如果省略 fmt,则数据将转换为系统默认格式的日期值。 如果 str 为 null,则该函数返回 null。 如果 fmt 是 J,对于 Julian,则 char 必须是整数。 如果无法转换为 DATE,则该函数返回错误。
7.12.9.3. 示例
select to_date('50-11-28 ','RR-MM-dd ');
to_date
---------------------
1950-11-28 00:00:00
(1 row)
select to_date(2454336, 'J');
to_date
---------------------
2007-08-23 00:00:00
(1 row)
select to_date('2019/11/22', 'yyyy-mm-dd');
to_date
---------------------
2019-11-22 00:00:00
(1 row)
select to_date('20-11-28 10:14:22','YY-MM-dd hh24:mi:ss');
to_date
---------------------
2020-11-28 10:14:22
(1 row)
select to_date('2019/11/22');
to_date
---------------------
2019-11-22 00:00:00
(1 row)
select to_date('2019/11/27 10:14:22');
to_date
---------------------
2019-11-27 10:14:22
(1 row)
select to_date('2020','RR');
to_date
---------------------
2020-01-01 00:00:00
(1 row)
select to_date(NULL);
to_date
---------
(1 row)
select to_date('-4712-07-23 14:31:23', 'syyyy-mm-dd hh24:mi:ss');
to_date
----------------------
-4712-07-23 14:31:23
(1 row)7.12.10. TO_TIMESTAMP
7.12.10.1. 目的
TO_TIMESTAMP(str,[fmt]) 根据给定的格式将输入参数 str 转换为不带时区的时间戳。 如果省略 fmt,则数据将转换为系统默认格式中不带时区值的时间戳。 如果 str 为 null,则该函数返回 null。 如果无法转换为不带时区的时间戳,则该函数返回错误。
7.12.10.3. 示例
select to_timestamp(1212121212.55::numeric);
to_timestamp
---------------------------
2008-05-30 12:20:12.55
(1 row)
select to_timestamp('2020/03/03 10:13:18 +5:00', 'YYYY/MM/DD HH:MI:SS TZH:TZM');
to_timestamp
------------------------
2020-03-03 13:13:18
(1 row)
select to_timestamp(NULL,NULL);
to_timestamp
--------------
(1 row)7.12.12. TO_YMINTERVAL
7.12.12.1. 目的
TO_YMINTERVAL(str) 将输入参数 str 时间间隔转换为年到月范围内的时间间隔。 只处理年月,其他部分省略。 如果输入参数为NULL,函数返回NULL,如果输入参数格式错误,函数返回错误。
7.12.12.2. 参数
str 输入参数(text,可以隐式转换为文本类型,必须是时间间隔格式。 兼容 SQL 标准的 SQL 间隔格式, ISO 持续时间格式与 ISO 8601:2004 标准兼容)。
7.12.12.3. 示例
select to_yminterval('P1Y-2M2D');
to_yminterval
---------------
10 mons
(1 row)
select to_yminterval('P1Y2M2D');
to_yminterval
---------------
1 year 2 mons
(1 row)
select to_yminterval('-P1Y2M2D');
to_yminterval
------------------
-1 years -2 mons
(1 row)
select to_yminterval('-P1Y2M2D');
to_yminterval
------------------
-1 years -2 mons
(1 row)
select to_yminterval('-01-02');
to_yminterval
------------------
-1 years -2 mons
(1 row)7.12.13. TO_DSINTERVAL
7.12.13.1. 目的
TO_DSINTERVAL(str) 将输入参数 str 的时间间隔转换为天到秒范围内的时间间隔。 输入参数包括:日、时、分、秒和微秒。 如果输入参数为NULL,函数返回NULL,如果输入参数包含年月或格式错误,函数返回错误。
7.12.13.2. 参数
str 输入参数(text,可以隐式转换为文本类型,必须是时间间隔格式。 兼容 SQL 标准的 SQL 间隔格式, ISO 持续时间格式与 ISO 8601:2004 标准兼容)。
7.12.13.3. 示例
select to_dsinterval('100 00 :02 :00');
to_dsinterval
-------------------
100 days 00:02:00
(1 row)
select to_dsinterval('-100 00:02:00');
to_dsinterval
---------------------
-100 days -00:02:00
(1 row)
select to_dsinterval(NULL);
to_dsinterval
---------------
(1 row)
select to_dsinterval('-P100D');
to_dsinterval
---------------
-100 days
(1 row)
select to_dsinterval('-P100DT20H');
to_dsinterval
---------------------
-100 days -20:00:00
(1 row)
select to_dsinterval('-P100DT20S');
to_dsinterval
---------------------
-100 days -00:00:20
(1 row)7.12.14. TO_TIMESTAMP_TZ
7.12.14.1. 目的
TO_TIMESTAMP_TZ(str,[fmt]) 根据给定的格式将输入参数 str 转换为带时区的时间戳。 如果省略 fmt,则数据将转换为具有系统默认格式带时区值的时间戳。 如果 str 为 null,则该函数返回 null。 如果无法转换为带时区的时间戳,则该函数返回错误。
7.12.14.3. 示例
select to_timestamp_tz('2019','yyyy');
to_timestamp_tz
------------------------
2019-01-01 00:00:00+08
(1 row)
select to_timestamp_tz('2019-11','yyyy-mm');
to_timestamp_tz
------------------------
2019-11-01 00:00:00+08
(1 row)
select to_timestamp_tz('2003/12/13 10:13:18 +7:00');
to_timestamp_tz
------------------------
2003-12-13 11:13:18+08
(1 row)
select to_timestamp_tz('2019/12/13 10:13:18 +5:00', 'YYYY/MM/DD HH:MI:SS TZH:TZM');
to_timestamp_tz
------------------------
2019-12-13 13:13:18+08
(1 row)
select to_timestamp_tz(NULL);
to_timestamp_tz
-----------------
(1 row)7.12.15. GREATEST
7.12.15.3. 示例
select greatest('a','b','A','B');
greatest
----------
b
(1 row)
select greatest(',','.','/',';','!','@','?');
greatest
----------
@
(1 row)
select greatest('瀚','高','数','据','库');
greatest
----------
高
(1 row)
SELECT greatest('HARRY', 'HARRIOT', 'HARRA');
greatest
----------
HARRY
(1 row)
SELECT greatest('HARRY', 'HARRIOT', NULL);
greatest
----------
(1 row)
SELECT greatest(1.1, 2.22, 3.33);
greatest
----------
3.33
(1 row)
SELECT greatest('A', 6, 7, 5000, 'E', 'F','G') A;
a
---
G
(1 row)7.12.16. LEAST
7.12.16.3. 示例
SELECT least(1,' 2', '3' );
least
-------
1
(1 row)
SELECT least(NULL, NULL, NULL);
least
-------
(1 row)
SELECT least('A', 6, 7, 5000, 'E', 'F','G') A;
a
------
5000
(1 row)
select least(1,3,5,10);
least
-------
1
(1 row)
select least('a','A','b','B');
least
-------
A
(1 row)
select least(',','.','/',';','!','@');
least
-------
!
(1 row)
select least('瀚','高','据','库');
least
-------
库
(1 row)
SELECT least('HARRY', 'HARRIOT', NULL);
least
-------
(1 row)7.12.17. NANVL
7.12.17.1. 目的
NANVl(str1, str2) 当str2为NaN时,返回一个替代值str1(当str2和str1都为NaN时,返回NaN;当str2或str1为null时,返回null)。 如果输入参数不能转换为real或float8类型,则函数返回错误。
7.12.17.3. 示例
SELECT nanvl('NaN', 'NaN');
nanvl
-------
NaN
(1 row)
SELECT nanvl(12345::float4, 1), nanvl('NaN'::float4, 1);
nanvl | nanvl
-------+-------
12345 | 1
(1 row)
SELECT nanvl(12345::float4, '1'::varchar), nanvl('NaN'::float4, '1'::varchar);
nanvl | nanvl
-------+-------
12345 | 1
(1 row)
SELECT nanvl('12345', 'asdf');
nanvl
-------
12345
(1 row)7.12.17.4. fmt(日期/时间格式的模板模式)
模式 |
描述 |
HH |
一天中的小时 (01-12) |
HH12 |
一天中的小时 (01-12) |
HH24 |
一天中的小时 (00-23) |
MI |
分钟 (00-59)minute (00-59) |
SS |
秒(00-59) |
MS |
毫秒(000-999) |
US |
微秒(000000-999999) |
SSSS |
午夜后的秒(0-86399) |
AM, am, PM or pm |
正午指示器(不带句号) |
A.M., a.m., P.M. or p.m. |
正午指示器(带句号) |
Y,YYY |
带逗号的年(4 位或者更多位) |
YYYY |
年(4 位或者更多位) |
YYY |
年的后三位 |
YY |
年的后两位 |
Y |
年的最后一位 |
IYYY |
ISO 8601 周编号方式的年(4 位或更多位) |
IYY |
ISO 8601 周编号方式的年的最后 3 位 |
IY |
ISO 8601 周编号方式的年的最后 2 位 |
I |
ISO 8601 周编号方式的年的最后一位 |
BC, bc, AD或者ad |
纪元指示器(不带句号) |
B.C., b.c., A.D.或者a.d. |
纪元指示器(带句号) |
MONTH |
全大写形式的月名(空格补齐到 9 字符) |
Month |
全首字母大写形式的月名(空格补齐到 9 字符) |
month |
全小写形式的月名(空格补齐到 9 字符) |
MON |
简写的大写形式的月名(英文 3 字符,本地化长度可变) |
Mon |
简写的首字母大写形式的月名(英文 3 字符,本地化长度可变) |
mon |
简写的小写形式的月名(英文 3 字符,本地化长度可变) |
MM |
月编号(01-12) |
DAY |
全大写形式的日名(空格补齐到 9 字符) |
Day |
全首字母大写形式的日名(空格补齐到 9 字符) |
day |
全小写形式的日名(空格补齐到 9 字符) |
DY |
简写的大写形式的日名(英语 3 字符,本地化长度可变) |
Dy |
简写的首字母大写形式的日名(英语 3 字符,本地化长度可变) |
dy |
简写的小写形式的日名(英语 3 字符,本地化长度可变) |
DDD |
一年中的日(001-366) |
IDDD |
ISO 8601 周编号方式的年中的日(001-371,年的第 1 日时第一个 ISO 周的周一) |
DD |
月中的日(01-31) |
D |
周中的日,周日(1)到周六(7) |
ID |
周中的 ISO 8601 日,周一(1)到周日(7) |
W |
月中的周(1-5)(第一周从该月的第一天开始) |
WW |
年中的周数(1-53)(第一周从该年的第一天开始) |
IW |
ISO 8601 周编号方式的年中的周数(01 - 53;新的一年的第一个周四在第一周) |
CC |
世纪(2 位数)(21 世纪开始于 2001-01-01) |
J |
儒略日(从午夜 UTC 的公元前 4714 年 11 月 24 日开始的整数日数) |
Q |
季度(to_date和to_timestamp会忽略) |
RM |
大写形式的罗马计数法的月(I-XII;I 是 一月) |
rm |
小写形式的罗马计数法的月(i-xii;i 是 一月) |
TZ |
大写形式的时区名称 |
tz |
小写形式的时区名称 |
OF |
时区偏移量 |
7.13. NLS_LENGTH_SEMANTICS参数
7.13.3. 用例
7.13.3.1. --测试“CHAR”
create table test(a varchar2(5));
CREATE TABLE
SET NLS_LENGTH_SEMANTICS TO CHAR;
SET
SHOW NLS_LENGTH_SEMANTICS;
nls_length_semantics
----------------------
char
(1 row)
insert into test values ('李老师您好');
INSERT 0 17.13.3.2. --测试“BYTE”
SET NLS_LENGTH_SEMANTICS TO BYTE;
SET
SHOW NLS_LENGTH_SEMANTICS;
nls_length_semantics
----------------------
byte
(1 row)
insert into test values ('李老师您好');
2021-12-14 15:28:11.906 HKT [6774] ERROR: value too long for type varchar2(5 byte)
2021-12-14 15:28:11.906 HKT [6774] STATEMENT: insert into test values ('李老师您好');
ERROR: value too long for type varchar2(5 byte)7.14. NVARCHAR2(size)
7.16. PL/iSQL
PL/iSQL 是 IvorySQL 的过程语言,用于为 IvorySQL 编写自定义函数、过程和包。 PL/iSQL 派生自 PostgreSQL 的 PL/pgsql,并增加了一些功能,但在语法上 PL/iSQL 更接近 Oracle 的 PL/SQL。 本文档描述了 PL/iSQL 程序的基本结构和构造。
7.16.1. PL/iSQL 程序的结构
iSQL 是一种程序化的块结构语言,支持四种不同的 程序类型,即 PACKAGES、PROCEDURES、FUNCTIONS 和 TRIGGERS。 iSQL 对每种类型的受支持程序使用相同的块结构。 一个块最多由三个部分组成:声明部分,可执行文件,和异常部分。 而声明和异常部分是可选的。
[DECLARE
declarations]
BEGIN
statements
[ EXCEPTION
WHEN <exception_condition> THEN
statements]
END;一个块至少可以由一个可执行部分组成 在 BEGIN 和 END 关键字中包含一个或多个 iSQL 语句。
CREATE OR REPLACE FUNCTION null_func() RETURN VOID AS
BEGIN
NULL;
END;
/所有关键字都不区分大小写。 标识符被隐式转换为小写,除非双引号, 就像它们在普通 SQL 命令中一样。 声明部分可用于声明变量和游标,并取决于使用块的上下文, 声明部分可以以关键字 DECLARE 开头。
CREATE OR REPLACE FUNCTION null_func() RETURN VOID AS
DECLARE
quantity integer := 30;
c_row pg_class%ROWTYPE;
r_cursor refcursor;
CURSOR c1 RETURN pg_proc%ROWTYPE;
BEGIN
NULL;
end;
/可选的异常部分也可以包含在 BEGIN - END 块中。 异常部分以关键字 EXCEPTION 开始,一直持续到它出现的块的末尾。 如果块内的语句抛出异常,程序控制转到异常部分,根据异常和异常部分的内容,可能会或不会处理抛出的异常。
CREATE OR REPLACE FUNCTION reraise_test() RETURN void AS
BEGIN
BEGIN
RAISE syntax_error;
EXCEPTION
WHEN syntax_error THEN
BEGIN
raise notice 'exception % thrown in inner block, reraising', sqlerrm;
RAISE;
EXCEPTION
WHEN OTHERS THEN
raise notice 'RIGHT - exception % caught in inner block', sqlerrm;
END;
END;
EXCEPTION
WHEN OTHERS THEN
raise notice 'WRONG - exception % caught in outer block', sqlerrm;
END;
/7.16.2. psql 对 PL/iSQL 程序的支持
要从 psql 客户端创建 PL/iSQL 程序,您可以使用类似于 PL/pgSQL 的$$语法
CREATE FUNCTION func() RETURNS void as
$$
..
end$$ language plisql;或者,您可以使用不带 $$ 的 Oracle 兼容语法的引用和语言规范, 并使用 /(正斜杠) 结束程序定义。 /(正斜杠)必须在换行符上
CREATE FUNCTION func() RETURN void AS
…
END;
/7.16.3. PL/iSQL 程序语法
7.16.3.1. PROCEDURES
CREATE [OR REPLACE] PROCEDURE procedure_name [(parameter_list)]
is
[DECLARE]
-- variable declaration
BEGIN
-- stored procedure body
END;
/7.16.3.2. FUNCTIONS
CREATE [OR REPLACE] FUNCTION function_name ([parameter_list])
RETURN return_type AS
[DECLARE]
-- variable declaration
BEGIN
-- function body
return statement
END;
/7.16.3.3. PACKAGES
7.16.3.3.1. PACKAGE HEADER
CREATE [ OR REPLACE ] PACKAGE [schema.] *package_name* [invoker_rights_clause] [IS | AS]
item_list[, item_list ...]
END [*package_name*];
invoker_rights_clause:
AUTHID [CURRENT_USER | DEFINER]
item_list:
[
function_declaration |
procedure_declaration |
type_definition |
cursor_declaration |
item_declaration
]
function_declaration:
FUNCTION function_name [(parameter_declaration[, ...])] RETURN datatype;
procedure_declaration:
PROCEDURE procedure_name [(parameter_declaration[, ...])]
type_definition:
record_type_definition |
ref_cursor_type_definition
cursor_declaration:
CURSOR name [(cur_param_decl[, ...])] RETURN rowtype;
item_declaration:
cursor_declaration |
cursor_variable_declaration |
record_variable_declaration |
variable_declaration |
record_type_definition:
TYPE record_type IS RECORD ( variable_declaration [, variable_declaration]... ) ;
ref_cursor_type_definition:
TYPE type IS REF CURSOR [ RETURN type%ROWTYPE ];
cursor_variable_declaration:
curvar curtype;
record_variable_declaration:
recvar { record_type | rowtype_attribute | record_type%TYPE };
variable_declaration:
varname datatype [ [ NOT NULL ] := expr ]
parameter_declaration:
parameter_name [IN] datatype [[:= | DEFAULT] expr]7.16.3.3.2. PACKAGE BODY
CREATE [ OR REPLACE ] PACKAGE BODY [schema.] package_name [IS | AS]
[item_list[, item_list ...]] |
item_list_2 [, item_list_2 ...]
[initialize_section]
END [package_name];
initialize_section:
BEGIN statement[, ...]
item_list:
[
function_declaration |
procedure_declaration |
type_definition |
cursor_declaration |
item_declaration
]
item_list_2:
[
function_declaration
function_definition
procedure_declaration
procedure_definition
cursor_definition
]
function_definition:
FUNCTION function_name [(parameter_declaration[, ...])] RETURN datatype [IS | AS]
[declare_section] body;
procedure_definition:
PROCEDURE procedure_name [(parameter_declaration[, ...])] [IS | AS]
[declare_section] body;
cursor_definition:
CURSOR name [(cur_param_decl[, ...])] RETURN rowtype IS select_statement;
body:
BEGIN statement[, ...] END [name];
statement:
[<<LABEL>>] pl_statments[, ...];7.17. 层级查询
7.17.1. 语法
{
CONNECT BY [ NOCYCLE ] [PRIOR] condition [AND [PRIOR] condition]... [ START WITH condition ]
| START WITH condition CONNECT BY [ NOCYCLE ] [PRIOR] condition [AND [PRIOR] condition]...
}CONNECT BY 查询语法以 CONNECT BY 关键字开头,这些关键字定义了父行和子行之间的分层相互依赖关系。 必须通过在 CONNECT BY 子句的条件部分指定 PRIOR 关键字来进一步限定结果.
PRIOR PRIOR 关键字是一元运算符,它将前一行与当前行联系起来。 此关键字可以用在相等条件的左边或右边。
START WITH 该子句指定从哪一行开始层次结构。
NOCYCLE 无操作语句。 目前只有语法支持。 该子句表示即使存在循环也返回数据。
8. 全局唯一索引
8.1. 创建全局唯一索引
8.1.3. 全局唯一性保证
在创建全局唯一索引期间,系统会对所有现有分区执行索引扫描,如果发现来自其他分区的重复项而不是当前分区,则会引发错误。例如:
命令
create table gidxpart (a int, b int, c text) partition by range (a);
create table gidxpart1 partition of gidxpart for values from (0) to (100000);
create table gidxpart2 partition of gidxpart for values from (100000) to (199999);
insert into gidxpart (a, b, c) values (42, 572814, 'inserted first on gidxpart1');
insert into gidxpart (a, b, c) values (150000, 572814, 'inserted second on gidxpart2');
create unique index on gidxpart (b) global;输出
ERROR: could not create unique index "gidxpart1_b_idx"
DETAIL: Key (b)=(572814) is duplicated.8.2. 插入和更新
8.2.2. 示例
命令
create table gidx_part (a int, b int, c text) partition by range (a);
create table gidxpart (a int, b int, c text) partition by range (a);
create table gidxpart1 partition of gidxpart for values from (0) to (10);
create table gidxpart2 partition of gidxpart for values from (10) to (100);
create unique index gidx_u on gidxpart using btree(b) global;
insert into gidxpart values (1, 1, 'first');
insert into gidxpart values (11, 11, 'eleventh');
insert into gidxpart values (2, 11, 'duplicated (b)=(11) on other partition');输出
ERROR: duplicate key value violates unique constraint "gidxpart2_b_idx"
DETAIL: Key (b)=(11) already exists.8.3. 附加和分离
8.3.1. 附加语句的全球唯一性保证
将新表附加到具有全局唯一索引的分区表时,系统将对所有现有分区进行重复检查。 如果在现有分区中发现与附加表中的元组匹配的重复项,则会引发错误并且附加失败。
附加需要所有现有分区上的共享锁(sharedlock)。 如果其中一个分区正在进行并发 INSERT,则附加将等待它先完成。 这可以在未来的版本中改进
8.3.2. 示例
运行命令
create table gidxpart (a int, b int, c text) partition by range (a);
create table gidxpart1 partition of gidxpart for values from (0) to (100000);
insert into gidxpart (a, b, c) values (42, 572814, 'inserted first on gidxpart1');
create unique index on gidxpart (b) global;
create table gidxpart2 (a int, b int, c text);
insert into gidxpart2 (a, b, c) values (150000, 572814, 'dup inserted on gidxpart2');
alter table gidxpart attach partition gidxpart2 for values from (100000) to (199999);输出
ERROR: could not create unique index "gidxpart1_b_idx"
DETAIL: Key (b)=(572814) is duplicated.